1.1 SVM
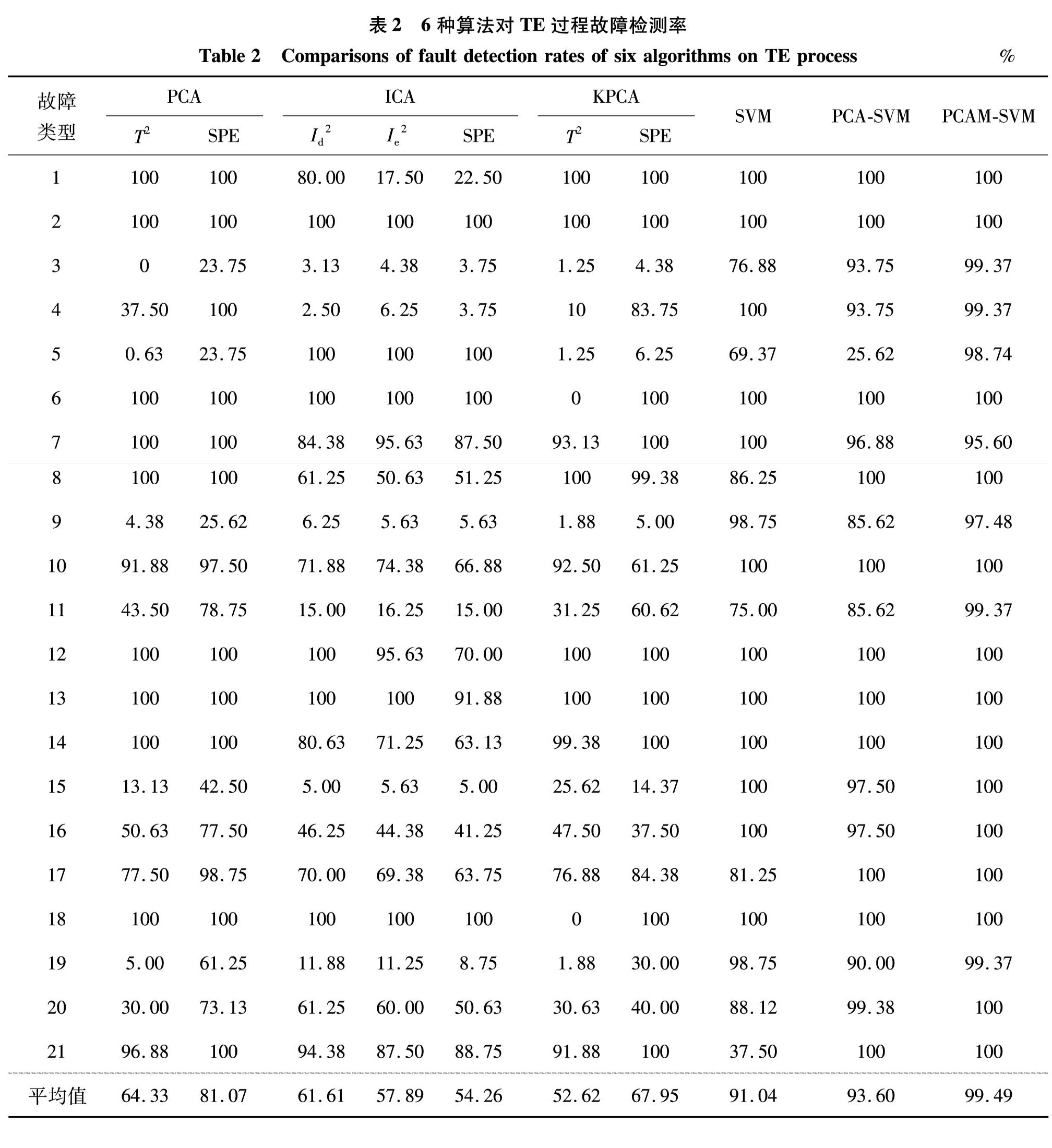
SVM[11-12]作为机器学习中的经典分类算法,在处理小规模数据集和非线性问题上有许多优点.对线性数据,SVM能够建立最大分离超平面对数据进行分类; 对非线性问题,需先将数据投影到高维空间,去除数据非线性再建立最大分离超平面,使数据被有效分类.由于分离平面是基于支持向量构造的,所以SVM是一种很好的解决高维问题的方案.
假设样本训练集为 H={(x1, y1),(x2, y2),…,(xm, ym)}, 样本类别yi∈{-1, 1}, 在样本空间中需要找到一个最大分离超平面,将样本划分为不同类别.SVM对指定数据分类的超平面(w, b)满足
wTx+b=0(1)
其中, 权重向量 w=(w1, w2, …, wm)Т; b为位移项; xi为样本空间中任意点.若(w, b)能够将样本正确分类,则对于(xi, yi)∈H, 有
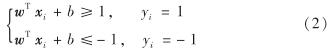
距离超平面最近的样本点使式(2)成立,此类样本点即为支持向量.两个异类支持向量到超平面的距离之和为间隔γ. 为找到最大间隔的超平面,实现最大程度分类,需找到满足式(2)的参数 w和b, 即SVM的基本型为

考虑到一些无法分类的样本,以及SVM在一些样本上可能分类错误,引入惩罚因子C和松弛变量ξi, 则式(3)可改写为
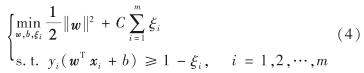
其中, ξi≥0, C>0.
将式(4)转化为对偶问题,使用拉格朗日乘数法求解,则该问题的拉格朗日函数为
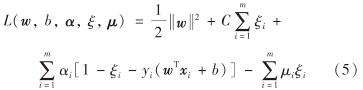
其中,拉格朗日乘子αi≥0, μi≥0,α=(α1, α2, …, αm), μ=(μ1, μ2, …, μm).
令L(w, b, α, ξi, μ)对w、 b和ξi的偏导为0,可得

对式(4)求解,得到模型
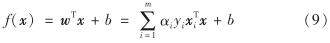
假设样本为非线性数据,为更好地实现分类,通过非线性映射φ(x)将数据投影到高维空间.为避免高维运算,引入核函数
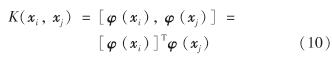
则通过核函数计算后模型(9)变为

因此,无论是在对线性还是非线性数据进行分类时,SVM都可将其有效转化,实现对数据高效准确地分类.
1.2 基于主元增广矩阵的SVM算法
在多元统计分析中,PCA能够达到降维并提取原始数据主要特征的目的.假设随机变量 xi的样本集表示为 X=[x1, x2, …, xm], m为样本数, xi∈Rn(i=1, 2, …, m), 则定义标准化后 X的协方差矩阵为
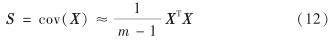
对S进行特征值分解,计算特征值和特征向量,并按照特征值降序排列,再求取主元个数z. 现有的选择主元得分个数的方法包括累计方差贡献率(cumulative percent variance, CPV)、碎石检验、平行分析和重建误差准则等方法,何种方法最佳,目前尚未达成共识.由于当CPV≥85%时,所获得的主元能够代表样本的主要特征[17-18],因此,本研究采用CPV方法.CPV的计算式为
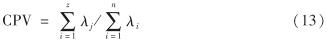
其中, λi为协方差矩阵的特征根.由前 z个特征向量构成的矩阵就是负载矩阵P, 则得分矩阵为
T=XP(14)
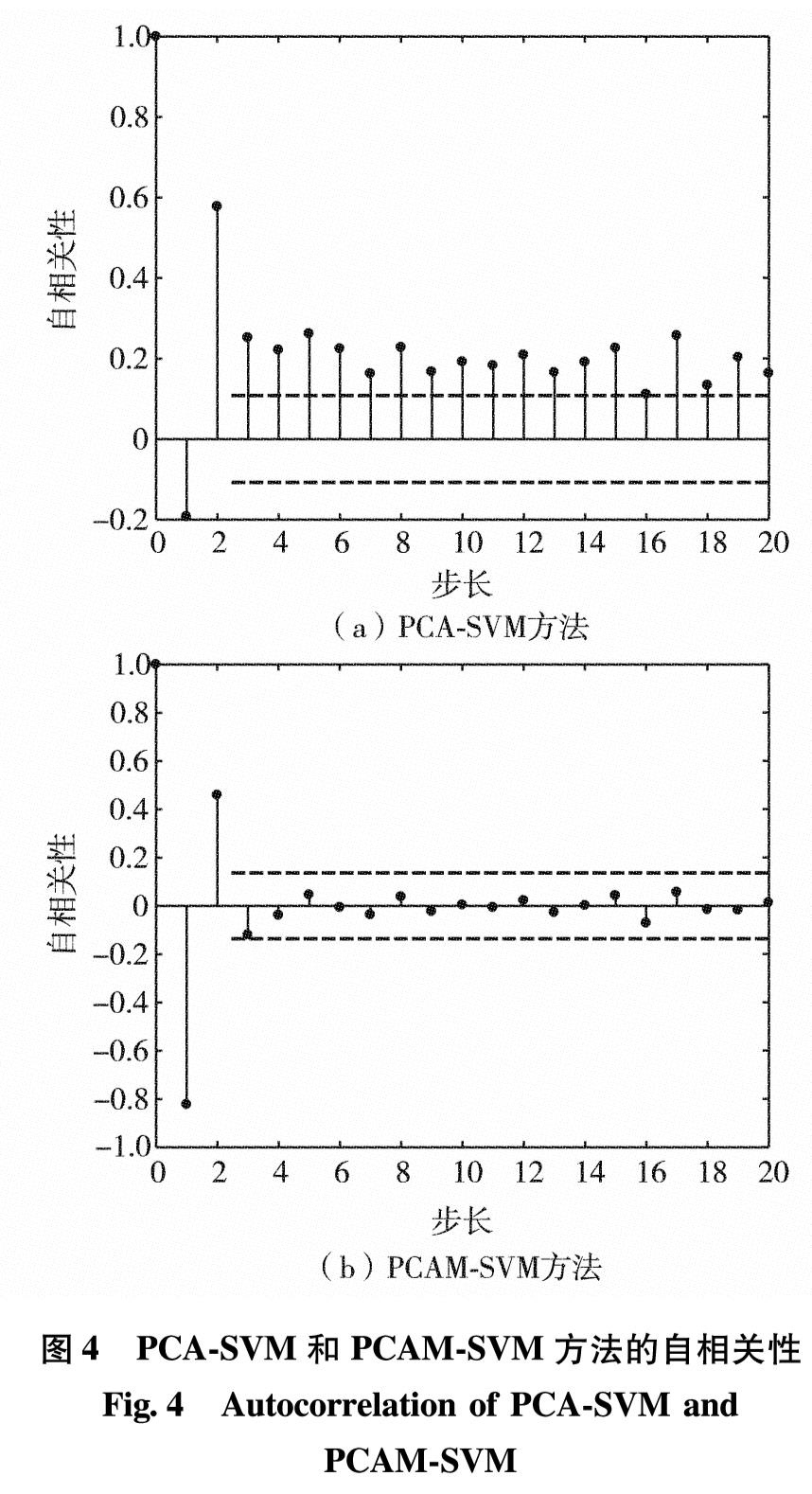
在动态主元分析(dynamic principal component analysis, DPCA)中,KU等[19]通过引入时滞特性实现了对过程静态信息和动态信息的同步提取,提高了故障检测性能.CHIANG等[20]指出,用时滞特性解决样本自相关性的思想在分类问题中能够减少类别与附加维度的重叠,只要数据充足并且增加维度合理,引入时滞特性就会带来良好的检测结果.ZHANG等[21]运用时差思想,通过建立不同的统计信息,消除了样本非线性对故障检测的影响,提高了工业过程的故障检测性能.本研究通过同时引入得分矩阵的时滞和时差特性来提升SVM算法的性能.
由式(14)可得正常数据在时刻t的得分 Tn(t), 然后构造时滞输入特性 Tn(t-1)和时差输入特性 Tn(t)-Tn(t-1), 并组合成增广矩阵
Tnormal=[Tn(t),Tn(t-1),Tn(t)-Tn(t-1)](15)
在故障操作条件下获取故障数据,同样通过PCA模型计算得分矩阵为 Tf, 在主元空间中构造出故障数据的增广矩阵为
Tfault=[Tf(t), Tf(t-1),Tf(t)-Tf(t-1)](16)
将 Tnormal与 Tfault作为SVM模型的训练数据,即 T<sub>train=[Tnormal, Tfault], 对SVM训练后获得判别分类函数.建立模型后,SVM能学习正常和故障数据的特性,进而对数据正确分类.将测试数据输入模型,通过超平面划分,将正常数据划分成一类并标记为0,故障数据划分成另一类并标记为1.
1.3 基于主元增广矩阵的SVM故障检测
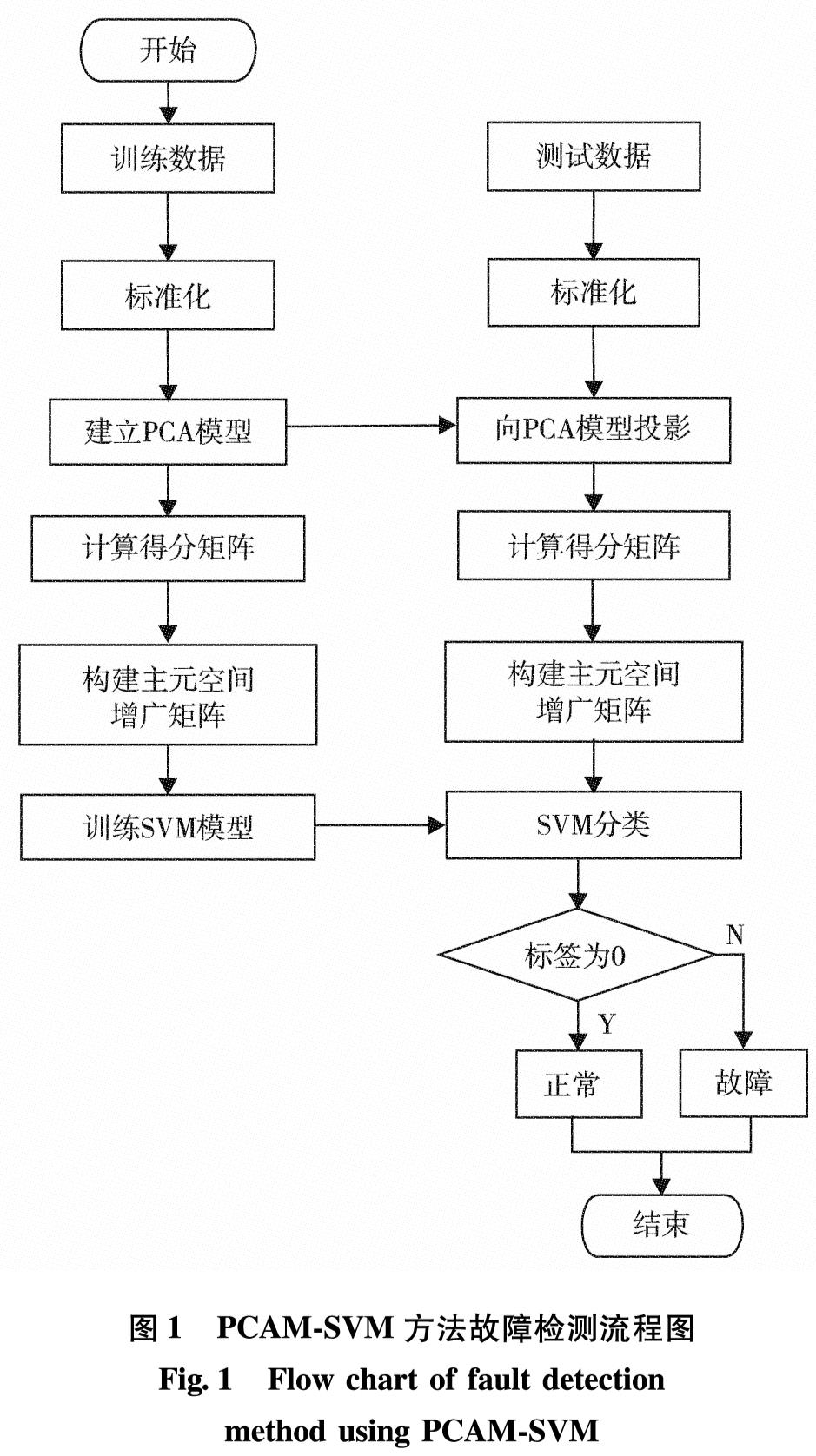
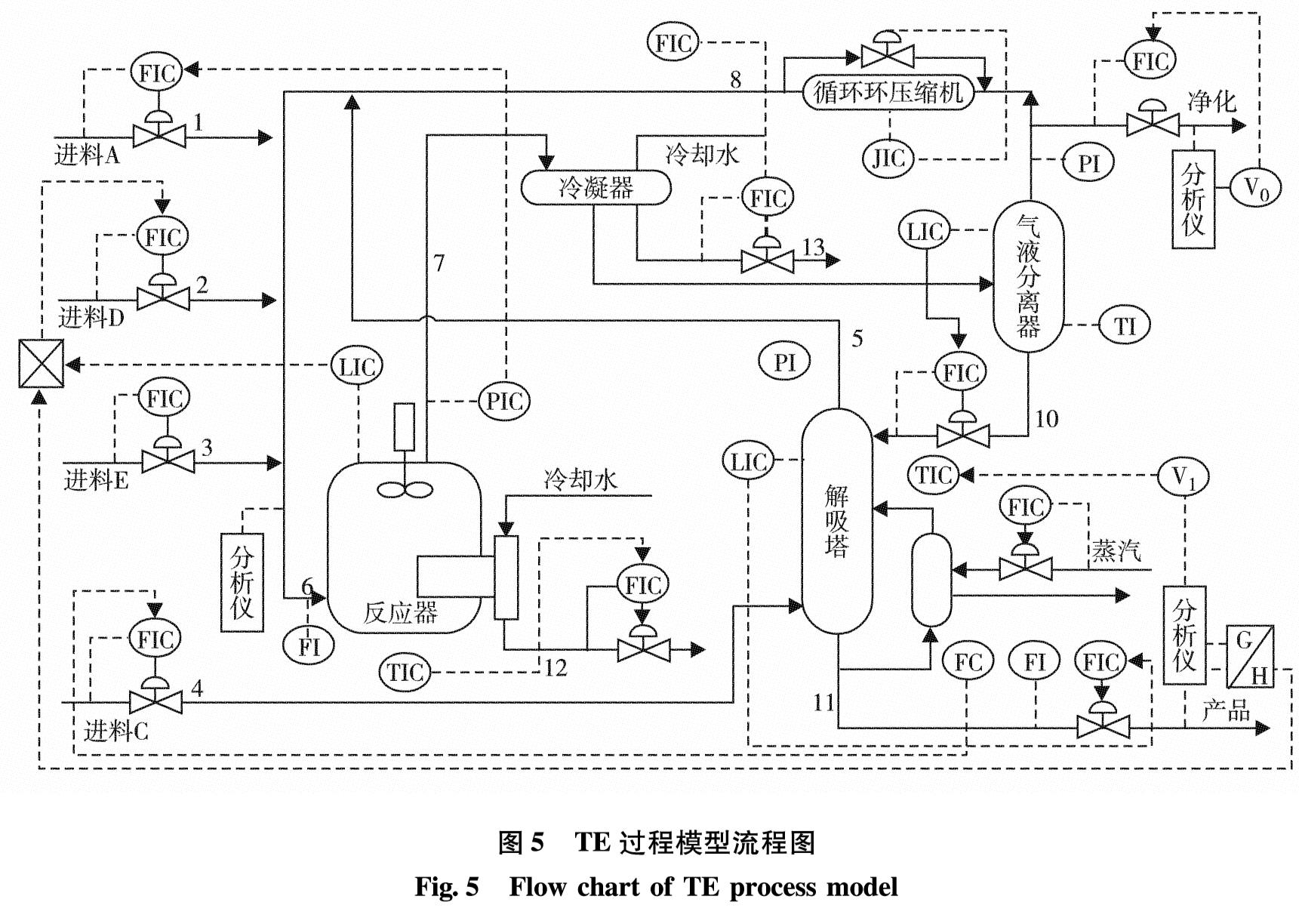
PCAM-SVM方法故障检测流程如图1.该方法主要包括离线模型建立和在线故障检测两个步骤.
图1 PCAM-SVM方法故障检测流程图
Fig.1 Flow chart of fault detection method using PCAM-SVM
离线模型建立具体步骤为:
1)采集正常操作条件下的数据集 X1和故障操作条件下的数据集 X2;
2)通过PCA建模在主元子空间分别计算正常和故障数据的得分矩阵 Tn和 Tf;
3)在时刻t的 Tn(t)和 Tf(t)中分别加入时滞输入特性和时差输入特性,并根据式(15)和(16)生成增广矩阵 Tnormal和 Tfault;
4)生成SVM训练数据集 Ttrain并对 Ttrain贴标签,正常数据标记为0,故障数据标记为1;
5)用 Ttrain训练SVM模型,获得判别分类函数.
在线故障检测具体步骤为:
1)利用离线建模数据的均值和方差,对测试数据集 xtest进行标准化;
2)将标准化后的测试数据投影到PCA模型上,采用式(14)计算得分矩阵 Tt;
3)在时刻t的Tt(t)中加入时滞和时差输入特性生成测试数据集的增广矩阵
Ttest'=[Tt(t), Tt(t-1), Tt(t)-Tt(t-1)](17)
即SVM模型的测试数据集;
4)将测试数据集的主元增广矩阵 Ttest' 送入SVM模型进行分类,正常数据标记为0,故障数据标记为1.