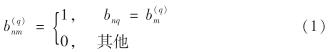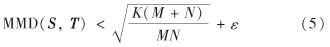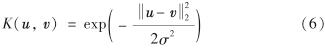4.1.1 自编码神经网络对混合属性数据集深度编码稳定性的影响
采用代入熵(re-substitution entropy, RE)[16]衡量混合属性数据集所转换的连续属性数据集所包含的信息量.对于给定的含有N个样本和D个连续属性的数据集

代入熵为
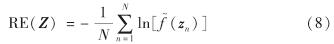
其中, f ~(z)为利用Parzen窗口法估计数据集Z的概率密度函数, z=(z1,z2,…,zD)为D维自变量,即

这里, hd是窗口宽度参数,且有
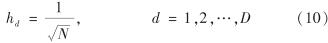
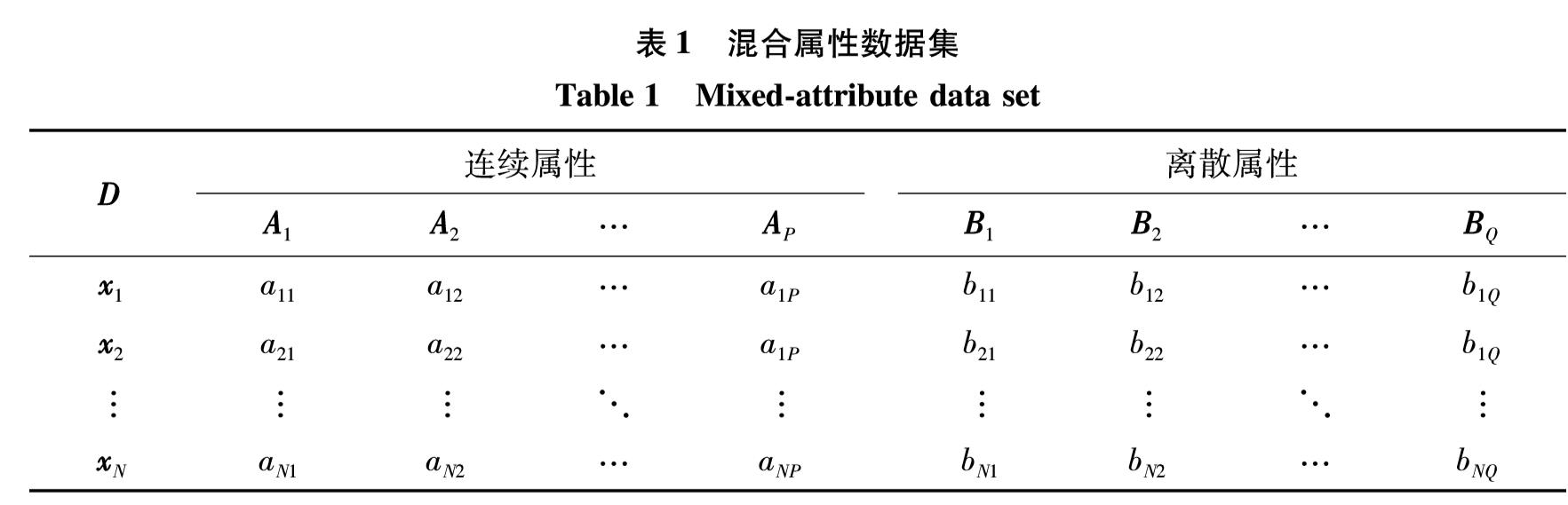
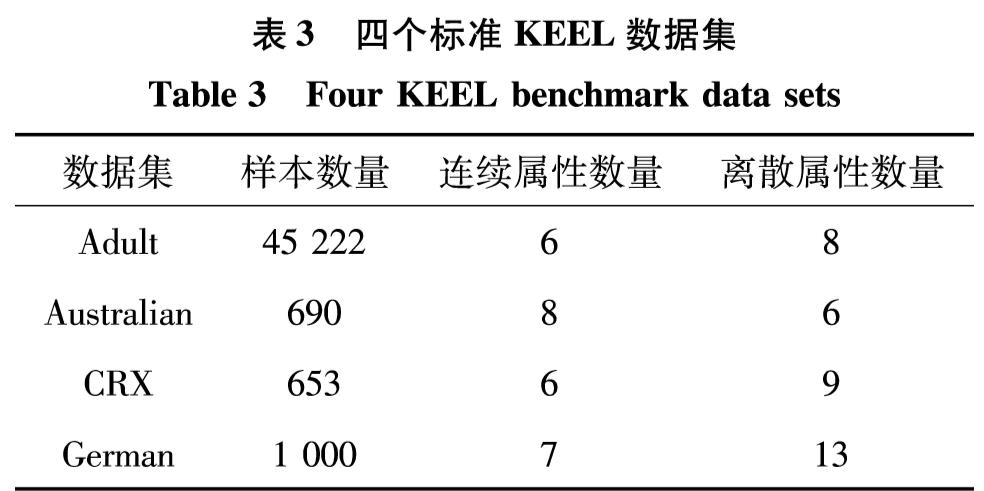
对每个数据集随机抽取200个样本,然后利用自编码神经网络(权重最多更新2 000次,终止阈值为1×10-4)进行属性转换,再计算转换后数据集的代入熵,重复该过程500次,并统计500个代入熵的均值m和标准差s. 图1给出了针对4个混合属性数据集的代入熵计算结果.
图1 自编码神经网络对混合属性数据集深度编码稳定性的影响
Fig.1 The impact of autocoder neural network on transformation of mixed-attribute data set
由图1可见,自编码神经网络能够稳定地对混合属性数据集进行深度编码,因为对于每一个数据集,500次转换的代入熵RE值基本上位于区间[m-3s, m+3s]内(Adult 数据集有498次、Australian数据集有500次、CRX数据集有499次、German数据集有499次).该实验证实了利用自编码神经网络对混合属性数据集进行深度编码是可行的,它基本能够保证转换后所得连续属性数据集所含信息量的稳定.
4.1.2 DE-MMD方法对非RSP和RSP数据块分布一致性的判定
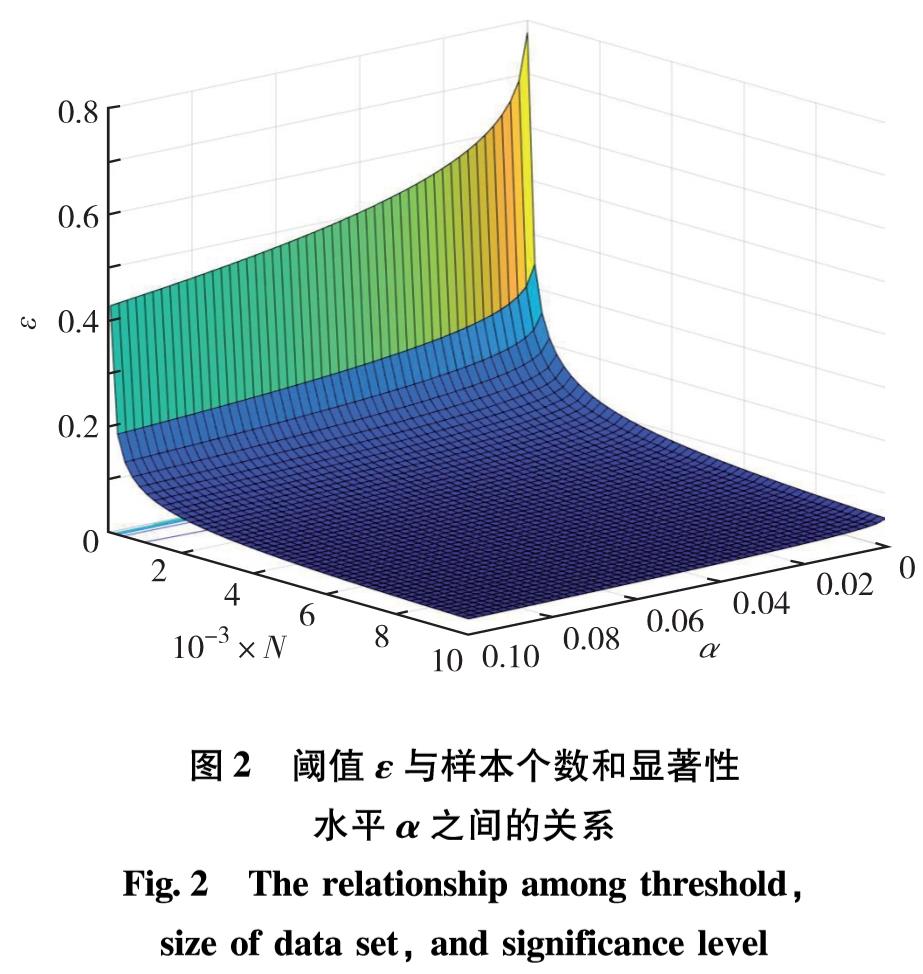
当利用DE-MMD方法判定不同数据集D1和D2的概率分布一致性时,从式(5)可发现阈值ε会对判定结果产生影响.由GRETTON等[7]的推导可知,当M=N时,

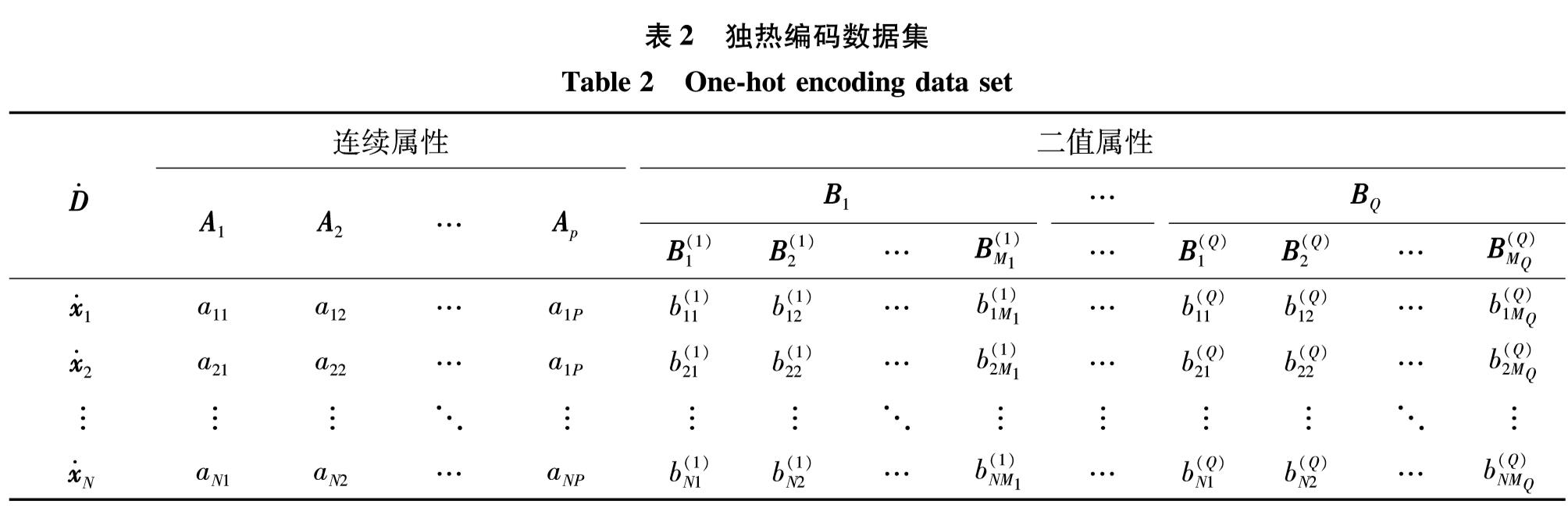
其中, K=1为式(6)所示的核函数上界; α为显著性水平.图2给出了N={100, 200, …, 10 000}和α={0.001, 0.002, …, 0.100}时,对应的ε取值情况.
图2 阈值ε与样本个数和显著性水平α之间的关系
Fig.2 The relationship among threshold, size of data set, and significance level
由图2可见,较小的样本数量和显著性水平对应较大的阈值,而较大的样本数量和显著性水平往往对应较小的阈值.在MMD方法的分布一致性判别式(式(5))中,发现阈值实际上仅与数据集的规模相关,而与数据集的具体性质无关.本研究给出一种基于“数据驱动”的方式来确定阈值.
首先,将式(5)修改为
MMD(S, T)<ε'(12)
其中, ε'为修正的一致性阈值,且ε'>0. 确定阈值ε'的具体流程为:
1)确定数据集 S的RSP数据块Si1、Si2和数据集T的RSP数据块Ti1、Ti2.其中,
|Si1|=|Si2|=1/2|S|(13)
|Ti1|=|Ti2|=1/2|T|(14)
RSP数据块的生成方法见文献[6,17],在此不再赘述.
2)分别计算MMD(Si1, Si2)和MMD(Ti1, Ti2)的值.
3)重复步骤1)和步骤2)I次,并令

针对表3中的每一个数据集分别抽取2个非RSP数据块和2个RSP数据块,使用DE-MMD方法分别度量非RSP数据块和RSP数据块之间的分布一致性.其中,两个数据块的规模均为200,自编码神经网络的权重最大更新次数为5×104,权重更新终止阈值为1×10-6, 一致性阈值计算公式执行I=10次, 核宽度σ2=9.
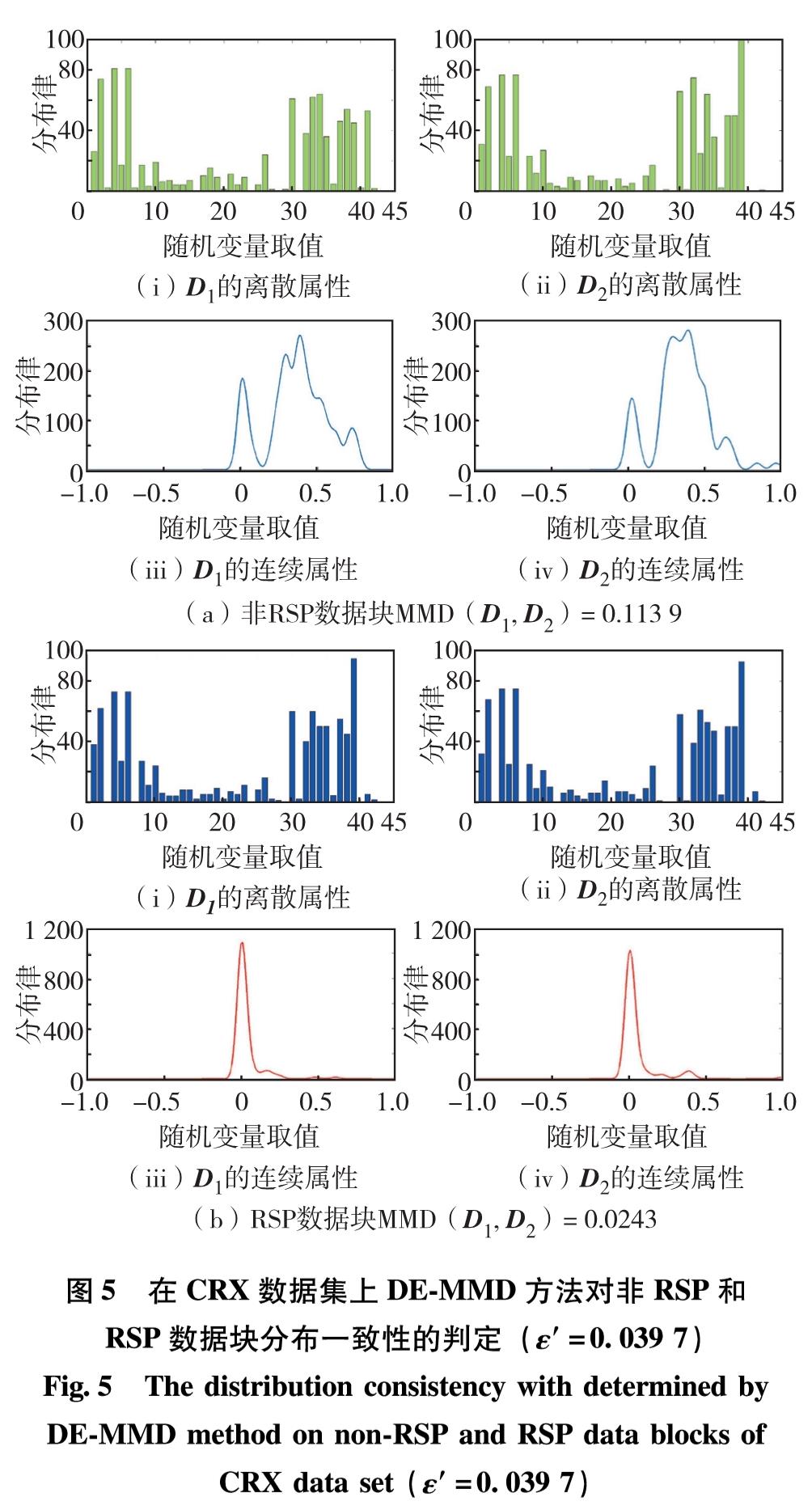
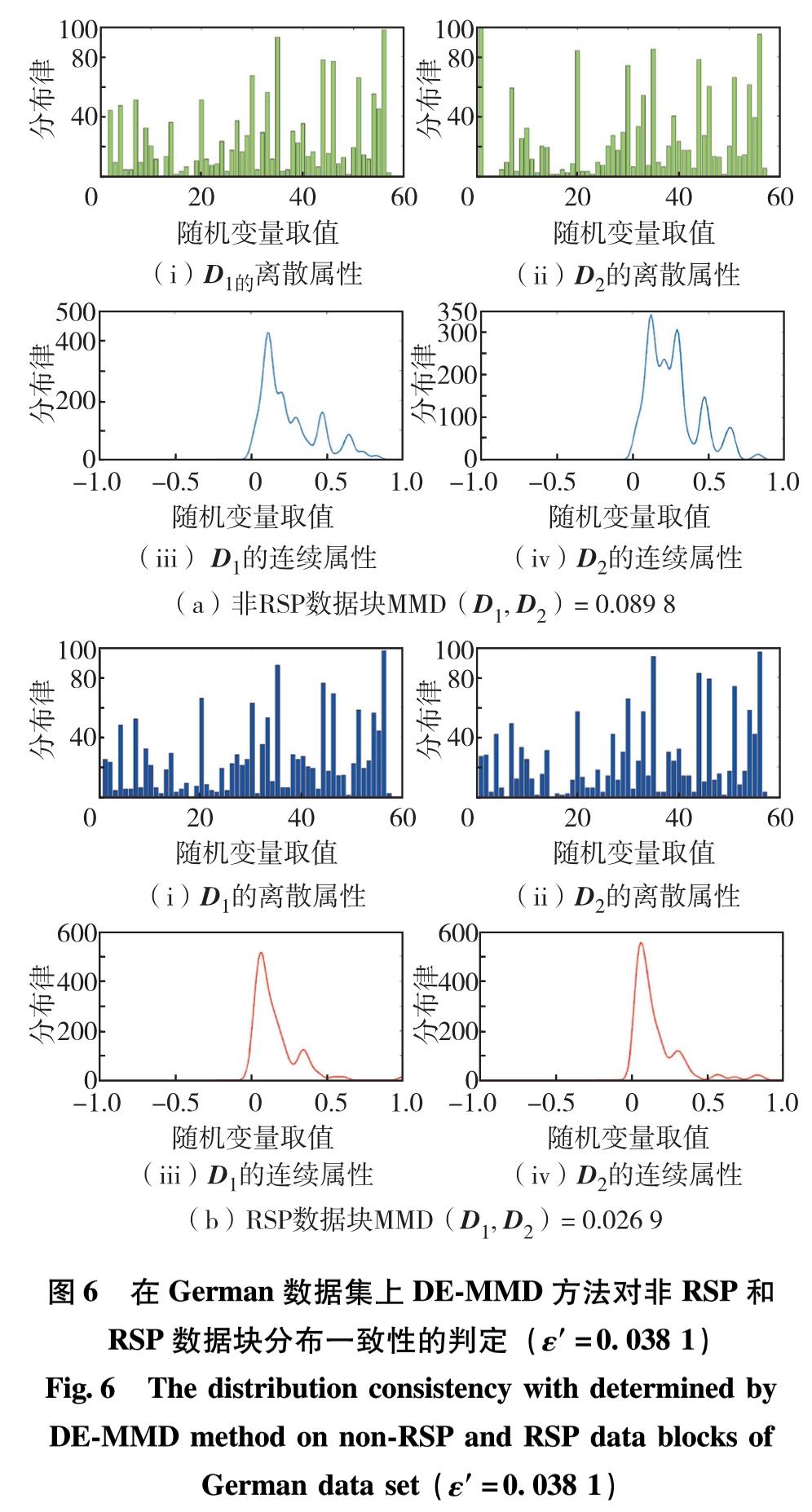
图3至图6分别显示了在4个混合属性数据集上DE-MMD方法对非RSP和RSP数据块分布一致性的判定情况.
图3 在Adult数据集上DE-MMD方法对非RSP和RSP数据块分布一致性的判定(ε'=0.013 1)
Fig.3 The distribution consistency determined by DE-MMD method on non-RSP and RSP data blocks of Adult data set(ε'=0.013 1)
图4 在Australian数据集上DE-MMD方法对非RSP和RSP数据块分布一致性的判定(ε'=0.109 8)
Fig.4 The distribution consistency with determined by DE-MMD method on non-RSP and RSP data blocks of Australian data set(ε'=0.109 8)
图5 在CRX数据集上DE-MMD方法对非RSP和RSP数据块分布一致性的判定(ε'=0.039 7)
Fig.5 The distribution consistency with determined by DE-MMD method on non-RSP and RSP data blocks of CRX data set(ε'=0.039 7)
图6 在German数据集上DE-MMD方法对非RSP和RSP数据块分布一致性的判定(ε'=0.038 1)
Fig.6 The distribution consistency with determined by DE-MMD method on non-RSP and RSP data blocks of German data set(ε'=0.038 1)
由图3至图6可见,对于非RSP数据块,其选定的离散属性和连续属性在分布上差异非常明显; 而对于RSP数据块,其选定的离散属性和连续属性在分布上基本保持了一致.对于非RSP数据块,MMD值不满足式(12),即不同数据块的MMD值大于阈值; 而对于RSP数据块,MMD值满足了式(12),即不同数据块的MMD值小于阈值.实验结果表明,DE-MMD方法能够量化不同混合属性数据集的概率分布一致情况并做出判定.
4.2 DE-MMD方法的有效性
4.2.1 基于离散属性独热编码的OE-MMD方法和离散属性二进制化的BSM方法
OE-MMD方法是基于表2的独热编码数据集,使用MMD方法对不同混合属性数据集的分布一致性进行检验.对于OE-MMD方法,同样使用式(12)判定数据块的分布一致性,阈值按照4.1.2节设计方法确定.
基于连续属性二进制化的BSM方法[8]首先对连续属性进行离散化处理,将混合属性数据集转换成离散属性数据集,为简便起见,在本实验对连续值属性采用二值离散化; 之后对离散属性数据集进行独热编码,得到独热编码数据集; 然后计算独热编码数据集对应的单项目集和双项目集的特征频率向量; 最后对单项目集和双项目集的特征频率向量进行归一化处理,得到混合属性数据集对应的特征向量.
BSM方法通过计算特征向量之间的距离判断混合属性数据集之间的相似性:距离越小,数据集相似性越高; 距离越大,数据集相似性越低.假设现有两个混合属性数据集对应的特征向量 w1=(w1,1, w1,2, …, w1,18)和 w2=(w2,1, w2,2, …, w2,18), 当
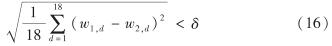
时,表明两个混合属性数据集具有相似的概率分布.其中, δ为相似性阈值,且δ>0.
4.2.2 DE-MMD方法与OE-MMD方法和BSM方法的比较
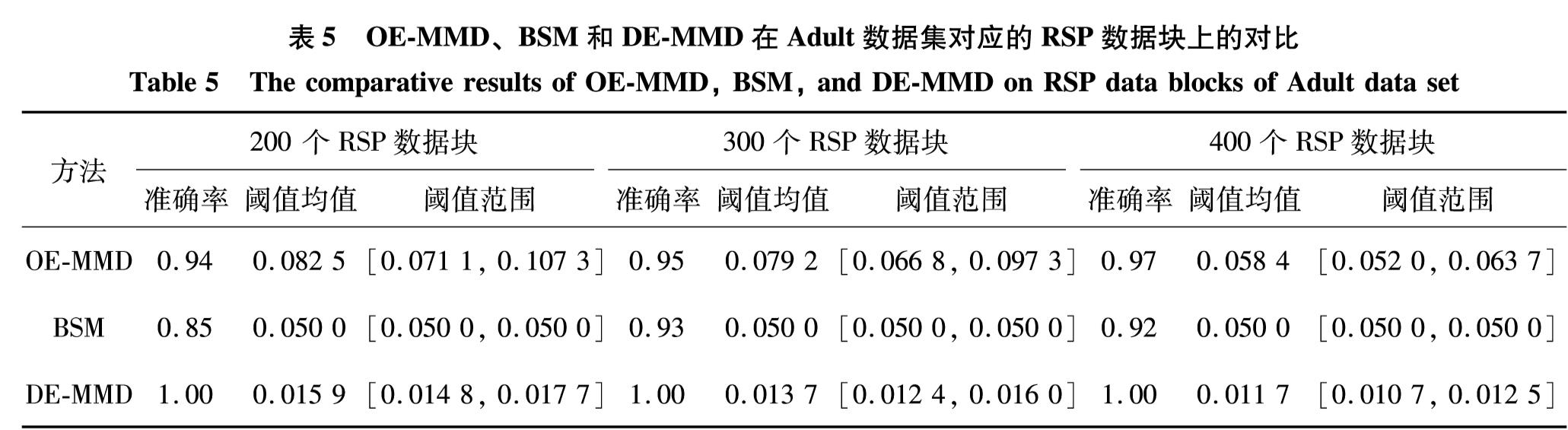
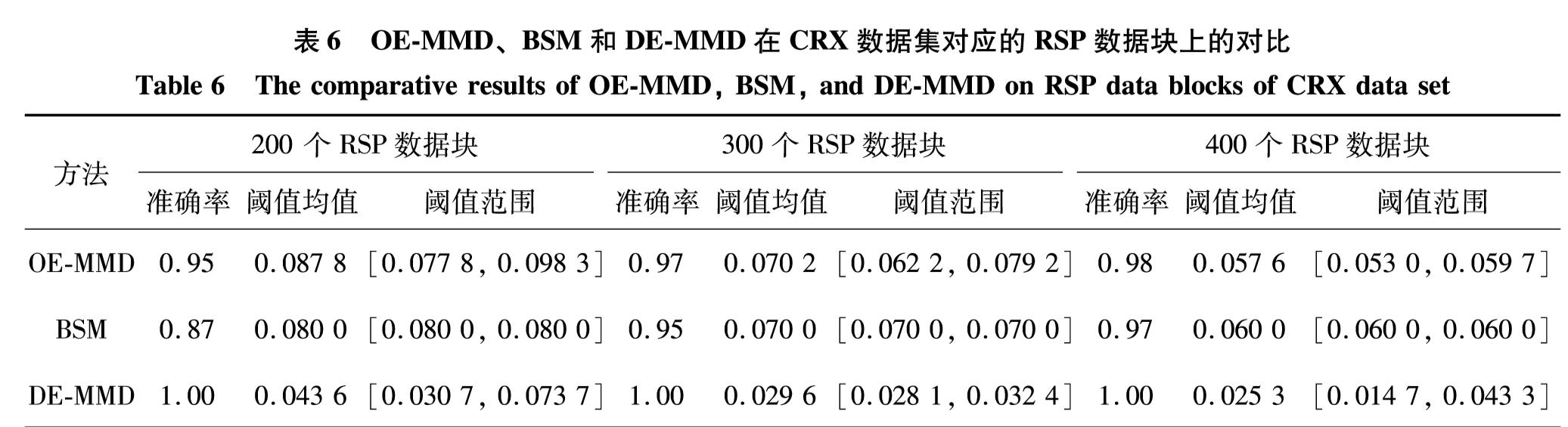
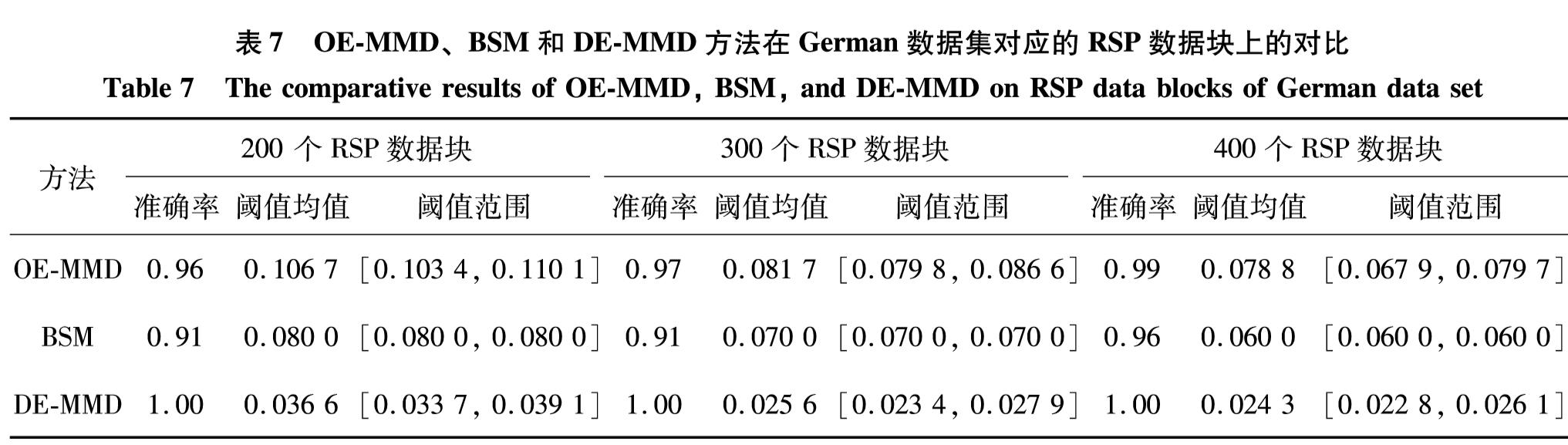
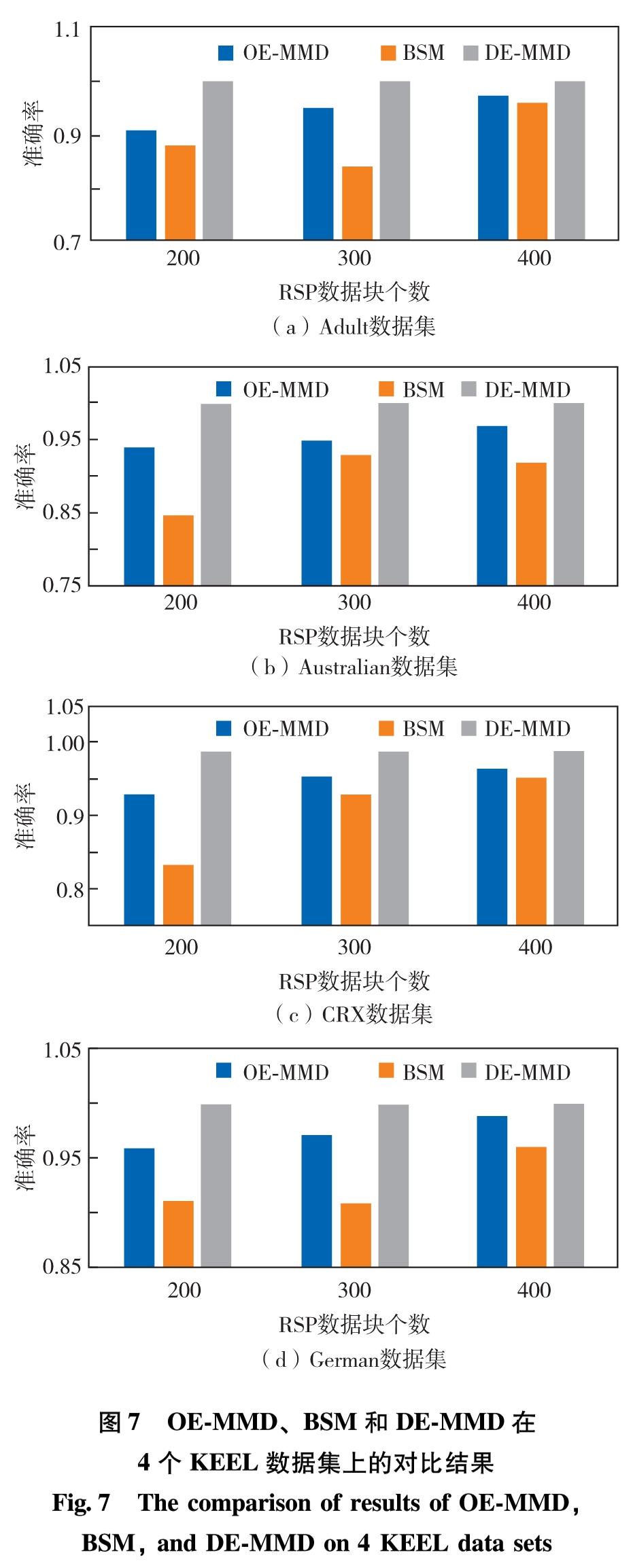
针对表3的每一个标准混合属性数据集,对其RSP数据块分别使用OE-MMD、BSM和DE-MMD方法进行概率分布一致性判定.其中,自编码神经网络的权重最大更新次数为5×104,权重更新终止阈值为1×10-6, I=10, 核宽度σ2=9. 针对每个数据集,选取3种不同规模(200、 300和400 个)的RSP数据块.对每种规模的数据块分别进行100次的分布一致性判定,并统计判定的准确率、阈值参数的选取,对比结果如表4—表7和图7所示.
RSP数据块具有一致的概率分布[5- 6],从对比结果可以发现,DE-MMD方法在4个混合分布数据集上均获得了优于OE-MMD和BSM方法的一致性判别准确率,证明本研究提出的DE-MMD方法是有效的.在此,本研究尝试对DE-MMD方法取得优势的原因进行讨论:① 与基于离散属性独热编码的OE-MMD方法相比,DE-MMD方法并没有直接使用0和1二值化的离散属性进行分布一致性度量,因为直接使用0和1的二值化离散属性在计算不同数据集的MMD值时容易增加式(4)失效的概率.举一个最极端情况的例子:假设有两组数据(1, 0)和(0, 1)以及(2, 2)和(1, 1), 经计算可发现这两组数据对应的MMD值相同,但是相比数据(1, 0)和(0, 1)之间的分布一致性,(2, 2)和(1, 1)应该具有更大的分布一致性.② 与基于连续属性二进制化的BSM方法相比,DE-MMD 方法是通过确定原始数据集的一种深度编码形式来计算数据集之间的分布一致性,这种深度编码通过输入和输出完全相同的神经网络将数据转化过程中的信息丢失率达到最小化,从而保证了基于深度编码的分布一致性能够反映原始数据的分布一致性.
表4 OE-MMD、BSM和DE-MMD在Australian数据集对应的RSP数据块上的对比
Table 4 The comparative results of OE-MMD, BSM, and DE-MMD on RSP data blocks of Australian data set
表5 OE-MMD、BSM和DE-MMD在Adult数据集对应的RSP数据块上的对比
Table 5 The comparative results of OE-MMD, BSM, and DE-MMD on RSP data blocks of Adult data set
表6 OE-MMD、BSM和DE-MMD在CRX数据集对应的RSP数据块上的对比
Table 6 The comparative results of OE-MMD, BSM, and DE-MMD on RSP data blocks of CRX data set
表7 OE-MMD、BSM和DE-MMD方法在German数据集对应的RSP数据块上的对比
Table 7 The comparative results of OE-MMD, BSM, and DE-MMD on RSP data blocks of German data set
图7 OE-MMD、BSM和DE-MMD在4个KEEL数据集上的对比结果
Fig.7 The comparison of results of OE-MMD, BSM, and DE-MMD on 4 KEEL data sets
结 语
提出一种新的基于深度编码和最大平均差异的混合属性数据集分布一致性度量方法DE-MMD,它能够对混合属性数据集的分布一致性进行有效度量,其表现优于基于离散属性独热编码的OE-MMD方法和基于连续属性二进制化的BSM方法.不同于OE-MMD方法和现有的BSM方法,DE-MMD方法并未直接使用0和1的二值离散属性表示连续属性也没有对连续属性进行离散化处理,因此不仅没有增加分布一致性判定过程中的不确定性,且最大限度地保留了原始数据集属性转化中的信息量.通过对自编码神经网络的使用,DE-MMD将原始数据集转换成可靠的深度编码表示形式,这对增强数据集分布一致性判定方法的稳定性起着至关重要的作用.
下一步研究计划结合不确定性理论深入分析DE-MMD方法的优势,尝试采用JS散度替换MMD进行分布一致性的度量,并考虑将DE-MMD方法应用到混合属性大数据的随机样本划分生成方法中,同时考虑使用极限学习机(extreme learning machine, ELM)[18-19]替换本研究的自编码神经网络以提升DE-MMD方法的判别速率.
致谢: 衷心感谢张晓亮博士对本文数学公式的推导及检查.