LIU Zhenchang,QU Shen,CHEN Shiming,et al.Exploration on the construction of university data ecosystem[J].Journal of Shenzhen University Science and Engineering,2020,37(Suppl.1):139-145.[doi:10.3724/SP.J.1249.2020.99139]
Network Security and Information Office of Party Committee, Nankai University, Tianjin 300071, P.R.China
education informatization; data quality; data management; ecological system
DOI: 10.3724/SP.J.1249.2020.99139
备注
随着教育信息化的逐步深入,数据已经成为保障学校信息化持续健康发展的最重要资产,数据质量的好坏直接影响着高校信息化未来发展的方方面面. 为提高数据质量,很多高校都开展了数据治理工作,但对于学校信息化发展步伐,数据治理的速度相对缓慢,无法完全满足各项工作对数据的要求. 针对该问题,南开大学因地制宜,积极探索改革,修订数据治理框架和技术路线,使数据治理及服务形成可持续发展的生态,解决了数据治理速度缓慢问题,实现了数据质量的快速提升.
With the gradual deepening of education informatization, data has become the most important asset to ensure the sustainable and healthy development of school informatization. The quality of data directly affects all aspects of the future development of university informatization. In order to improve the quality of data, many colleges and universities have carried out the work of data governance. However, compared with the pace of the development of school informatization, the speed of data governance is always relatively slow, which can not fully meet the requirements of various work on data. In view of this problem, Nankai University actively explores the reform and revises the data governance framework and technical route according to local conditions, so as to form a sustainable development ecology for data governance and services, solve the slow speed of data governance, and realize the rapid improvement of data quality.
引言
近年来,随着高校数字化校园建设的快速推进,业务系统和各类应用几乎已经覆盖学校的每一个场景,给师生的工作、学习与生活都带来了极大的便利. 数据作为业务系统和各类应用的基础,已经成为保障学校信息化持续健康发展的最重要资产,对于支撑高校教学、科研和管理,服务高校 “双一流”建设,完善学校治理体系,提升核心竞争力等,正发挥着越来越重要的作用. 数据质量的好坏直接影响着高校信息化未来发展的方方面面. 因此,如何通过数据治理工作来提高数据质量就成为很多高校老师关注的课题.
许晓东等[1]认为数据治理是提高大学教育治理、决策科学性和管理效率的需要,其高效、负责、透明等特征符合高等教育治理要求,数据治理的有效实施可以使大学变得更加智慧和敏捷. 彭雪涛[2]认为中国高校应充分认识数据资产的价值和风险,以数据治理为指引,培育数据共建共享的协同环境. 余鹏等[3]建立基于“服务治理”与“数据治理”模式的数据生态闭环体系,使数据综合应用成果得以有效应用于教学、科研、校务管理与科学决策的全过程,促进全面提升高校核心竞争力取得成效,是教育信息化数据工作的核心内容. 学者们一致认为数据治理对高校未来发展具有极其重要的意义,普遍认为高校应培育数据共建共享的协同环境,营造完整闭环的数据治理生态体系.
本研究介绍国内外数据治理研究的现状,分析高校在开展数据治理工作中遇到的普遍问题. 以南开大学为原型,介绍如何因地制宜,积极探索改革,修订数据治理框架和技术路线,使数据治理及服务形成可持续发展的生态,解决数据治理速度缓慢问题,实现数据质量的快速提升.
1 数据治理研究现状
2 数据生态体系建设
3 结 语
以南开大学为原型,分析了高校在数据治理工作当中遇到的实际问题,通过不断探索改革,经历数据治理内部循环、加强数据治理内部循环和加强数据治理内外部双循环3个阶段,最终通过营造高校数据生态体系,实现了可持续快速提升数据质量的目的.
数据治理工作任重而道远,初期数据质量的提升取决于技术、平台和管理水平,后期则更多地取决于组织内参与数据治理人员整体的数据治理意识以及人才团队建设,这也是我们今后在数据治理工作中的重点.
南开大学自2007年启动数字校园建设后随即便开展了数据治理工作,先后搭建数据清洗整合平台、公共数据共享平台、数据质量监测平台和公共数据开放平台,制定《南开大学数据标准》和U/C矩阵,发布《南开大学数据管理规定(试行)》,确立信息化建设与管理办公室为学校数据的管理部门,明确数据生产单位和数据使用单位的权责. 现阶段,高校数据中心建设主要围绕消除数据孤岛,提升数据质量等问题展开,通过集中管理数据,强化职能部门责任意识等方式,实现数据在部门间互联互通、共享交换和逐步优化的目的. 南开大学按照这个模式开展数据治理工作多年,虽然已取得了阶段性成果,但对比学校信息化发展步伐,数据治理的速度总是显得相对缓慢,无法完全满足各项工作对数据的要求. 针对该问题,我们因地制宜,积极探索改革,修订数据治理框架和技术路线,通过不断实践,营造高校数据治理生态,最终将高校数据治理工作推向快速发展的通道.
2.1 数据治理框架南开大学数据治理生态体系整体框架如图3. 该体系框架设计以满足用户需求为驱动,以全面实现数据价值,服务教学、科研和管理为导向,以信息技术为支撑,在遵循《南开大学数据标准》和《南开大学数据管理规定》的前提下,注重保护数据安全和个人隐私,考虑重点关注域和促成因素,积极协调学校各相关部门,按照科学规范的工作流程,逐步形成完善可持续的数据治理协同工作机制,最终营造出良性持续的数据治理生态环境.

图3 南开大学数据治理生态体系总体框架
自下向上看,高校经过多年的数字化校园建设,积累了大量的业务数据,分散存储于各个业务系统中. 为促进数据共享,实现数据在不同部门间互联互通,学校在遵守数据安全和保护个人隐私的前提下,以需求为驱动,建立校级中心数据库(共享库),通过使用数据抽取工具将数据从各业务系统中采集并集中存储到中心数据库中. 由于原始数据质量参差不齐,无法直接提供给数据使用部门使用,需要对原始数据进行数据清洗,使之符合高校数据标准规范. 为便于对数据进行管理维护,则根据实际需求对所有数据做进一步数据整理,将数据划分为原始数据层、主题数据层、统计分析数据层和应用数据层. 之后,通过数据开放平台向各数据使用部门提供共享数据接口,实现数据在各部门间的互联互通. 与此同时,为逐步提升中心数据库(共享库)中数据的质量,学校根据数据标准要求,通过数据质量管理平台,对数据质量进行检测,并结合数据使用部门对数据问题的各项反馈,生成《数据质量报告》,发送给数据生产部门,协调数据生产部门补充完善优化数据. 经过数据清洗和数据整理后的数据可提供给各数据使用部门,满足基础应用使用需求. 如支撑各单位业务系统建设,支撑个人用户数据中心和校、院两级主题数据画像的建设,学校“一表通”平台建设等. 经过长期的数据治理,在数据质量达到良好的情况下,可以对数据进行分析挖掘,满足学校对所关注领域数据分析预测预警的需求,从而最大化地实现数据价值.
2.2 数据治理技术路线数据质量作为决定数据生态建设效果的关键因素,可通过数据治理的内部和外部两个循环来予以保证(图4).
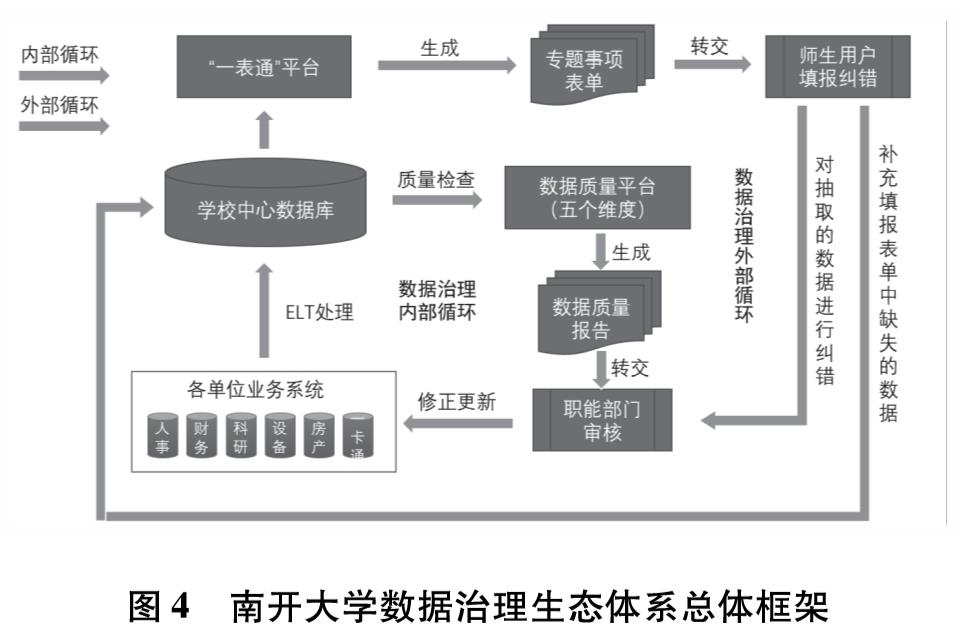
图4 南开大学数据治理生态体系总体框架
数据治理内部循环以校务管理为中心. 数据源自业务系统,通过ETL过程采集进入全量数据中心,通过数据质量平台进行质量检测分析,生成数据质量报告反馈到相关职能部门,通过修正更新业务系统的数据实现数据质量的提升.
数据治理外部循环以师生以及学院(研究所)为核心,通过数据开放平台、“一表通”平台等构建面向不同层面用户的数据应用与服务,一方面师生通过数据填报、数据分析和数据纠错等业务功能,产生数据并回流已有业务系统完成循环; 另一方面依托于数据生态体系构建的诸多数据应用,不断补充、产生新的业务领域数据,通过数据开放平台的数据双向流转支撑服务,直接回馈到数据中心,参与数据的整合清洗过程.
数据治理内部循环是当前高校普遍采用的数据治理模式,但在新形势下其效率已不足以满足需求.数据治理外部循环将师生用户引入到数据治理过程当中,对整个数据治理的过程进行监督评价,师生既是数据治理过程的参与者也是受益者,数据治理效果同用户体验紧密相关,可极大提高学校数据治理的效率.
2.3 数据治理实践2.3.1 数据治理具体实践南开大学自启动数据治理工作以来,一直在摸索提升数据治理效果的方案并不断进行实践改进. 到目前为止我校共实践了3种主要模式,分别是内部循环模式、加强内部循环模式和加强内外双循环模式.
在数据治理初期,我校采用的是数据治理内部循环模式,由学校信息化建设与管理办公室牵头,搭建校级数据清洗整合平台、公共数据共享平台和数据质量监测平台,制定《南开大学数据标准》和U/C矩阵,协调学校各数据生产/使用部门,初步实现了部分公共数据在校内的交换共享并提升了数据质量. 在此期间,由于部分部门对数据治理的意义认识不足,对数据治理工作配合度不够,因此无法完成对相应数据的治理工作. 为此,我们积极与学校领导沟通争取,由学校发布《南开大学公共数据管理规定(试行)》,规定中确立南开大学信息化建设与管理办公室作为学校数据的管理部门,明确各数据生产部门和数据使用部门的工作职责和权益. 从此学校的数据治理进入加强内循环模式,校内各部门配合度显著提高,数据覆盖面增加,数据质量也得到了较大提升,数据治理效果空前. 随着数据治理的逐步深入,发现各部门信息化发展水平参差不齐,还是有很多数据由于没建相应的业务系统所以无法提供电子版数据源. 为了解决这个问题,我们在加强内循环模式的基础下,积极引入数据外循环模式,形成数据治理加强内外双循环模式,双管齐下,数据治理效果显著.
2.3.2 数据治理实践模式对比表2展示了3种数据治理实践模式的不同之处.从数据治理效果来看,加强内外双循环模式最好. 但从复杂程度上看,加强内外双循环模式的复杂度也是最高的. 这种模式数据来源较多,若对数据流向缺乏了解,稍有不慎就容易出错,因此,需要对其进行精细的管理才能避免产生错误数据.

表2 数据治理实践模式对比
2.3.3 数据治理实践效果图5展示了南开大学数据治理在不同阶段的实践效果. 在数据治理前,数据质量水平较低. 在内循环初期,学校数据生产单位配合审核更新数据,数据质量在短期内得到提升,随后在内循环中、后期,由于部分单位配合不够,所以数据质量提升速度有所降低. 在加强内循环初期,根据《南开大学公共数据管理规定(试行)》,各数据生产单位积极配合,数据质量在短期内得到快速提升,随后在加强内循环中期、后期,由于数据生产单位掌握的电子数据有限,存在不掌握相关数据或仅有纸质版数据的问题,所以数据治理提升速度有所降低. 在加强内外双循环初期,师生积极参与数据治理,通过个人数据中心和“一表通”等应用积极参与修正或补充个人相关数据,数据质量短期内得到大幅提升.随后在加强内外双循环中、后期,数据生产单位、数据使用单位与师生个人用户协同配合越来越熟练,数据治理速度趋于平稳,学校数据生态体系逐渐形成,数据质量日益完善.
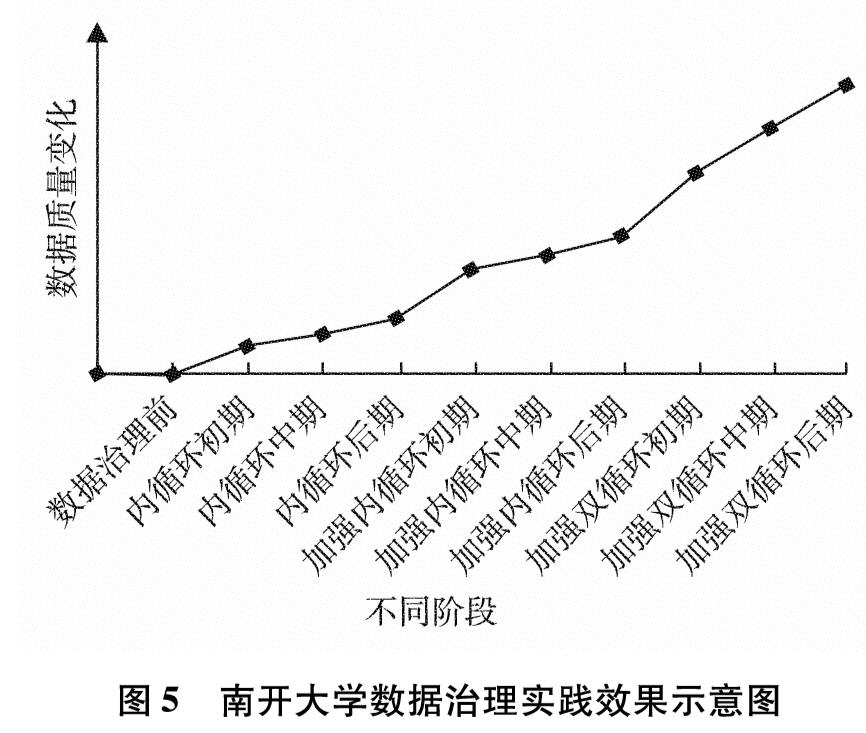
图5 南开大学数据治理实践效果示意图
- [1] 许晓东,王锦华.高等教育的数据治理研究[J].高等工程教育研究,2015(5):25-30.
- [2] 彭雪涛.美国高校数据治理及其借鉴[J].电化教育研究,2017(6):76-81.
- [3] 余 鹏,李 艳. 智慧校园视域下高等教育数据生态治理体系研究[J]. 中国电化教育,2020(400):88-100.
- [4] 张明英,潘 蓉.《数据治理白皮书》国际标准研究报告要点解读[J].信息技术与标准化,2015(6):54-57.
- [5] 董晓辉,郑小斌.高校教育大数据治理的框架设计与实施[J].中国电化教育, 2019(391):63-71.
- [6] 吴信东,董丙冰,堵新政,等.数据治理技术.软件学报,2019,30(9):2830-2856.
- [7] 许晓东,彭 娴,周 可.美国通用教育数据标准对我国高等教育数据治理的启示[J].高等工程教育研究,2019(1):103-108.
- [8] 中国信息通信研究院.数据资产管理实践白皮书(4.0版)[EB/OL]. [2019- 06- 04]http://www.caict.ac.cn/kxyj/qwfb/bps/201906/t20190604_200629.htm.
- [9] 李学龙,龚海刚.大数据系统综述[J].中国科学:信息科学,2015,45(1):1- 44.
- [10] 郭志懋,周傲英.数据质量和数据清洗研究综述[J].软件学报,2002(11):2076-2082.
- [11] 巫莉莉,张 波.高校数据治理中提升数据质量的方法研究[J].重庆理工大学学报自然科学版,2019,33(8):149-156.
- [12] 丁小欧,王宏志,张笑影,等.数据质量多种性质的关联关系研究[J].软件学报,2016,27(7):1626-1644.
- [13] 谷 斌.信息系统建设中的数据质量管理体系研究[J].情报杂志,2007(5):65- 67.
- [14] CHIRKOVA R, LIBKIN L, REUTTER J L. Tractable XML data exchange via relations//Proc. of the 20th ACM Int'l Conf. on Information and Knowledge Management. New York: ACM Press, 2011:1629-1638.
1.1 数据治理的定义关于数据治理的定义,目前尚未形成一个统一的说法. 国际数据管理协会认为数据治理是对数据资产管理行使权力和控制的活动集合. 国际数据治理研究所认为数据治理是一个通过一系列信息相关的过程来实现决策权和职责分工的系统,这些过程按照达成共识的模型来执行,该模型描述了谁能根据什么信息,在什么时间和情况下,用什么方法,采取什么行动.
2015年5月,中国代表团在巴西圣保罗召开的SC40/WG1(IT治理工作组)第3次工作组会议上提交了《数据治理白皮书》国际标准研究报告,提出数据是资产,通过服务产生价值,数据治理是在数据产生价值的过程中,治理团队对其的评价、指导和控制,是数据治理的最基本概念[4].
董晓辉等[5]基于权变理论,认为数据治理需要平衡组织内外众多利益群体的利益诉求,结合组织战略目标和数据现状,长期坚持并反复迭代优化. 吴信东等[6]认为数据治理是将一个机构(企业或政府部门)的数据作为战略资产来管理,需要从数据收集到处理应用的一套管理机制,以提高数据质量,实现广泛的数据共享,最终实现数据价值最大化. 上述对数据治理的描述虽然不同,但核心思想是一致的,都是指围绕数据资产,通过开展各项活动来不断提升数据质量,然后从数据中挖掘价值,并将其价值发挥到最大的过程.
1.2 数据治理的过程方法一般认为,数据治理全过程是在遵守“数据标准”和“数据管理规定”的前提下,围绕组织内的数据资产,按照数据采集、数据清洗、数据整理、数据交换和数据更新的闭环,不断循环迭代,逐渐提升数据质量[3,6],具体过程如图1.

图1 数据治理过程示意图
1.2.1 数据标准和数据管理规定数据标准是保障数据的内外部使用和交换的一致性和准确性的规范性约束. 数据管理规定是为规范完善数据的生产、管理和使用,充分发挥数据资源价值所做的各项具体约束. 数据标准是数据治理的基础,也是数据治理建设中的首要环节[7- 8]. 开展数据治理工作一般都是从制定数据标准和数据管理规定开始的,通过制定和发布统一的数据标准,结合制度约束和系统控制等手段,可以有效提高数据的完整性、有效性、一致性和规范性,进而推动数据的共享开放,构建统一的数据资产地图,为数据资产管理活动提供参考依据[7].
1.2.2 数据采集数据采集是指通过使用数据采集工具将不同来源、不同性质的分散数据抽取集中到一起的操作. 它是数据治理的第一个环节,主要作用是采集分散数据并集中存储,方便后续对数据进行清洗、整理和交换等,是数据治理闭环中的基础环节. 数据采集的数据类型包括结构化数据、半结构化数据和非结构化数据.
1.2.3 数据清洗数据清洗是指在数据集中找出不准确、不完整或不合理的“脏数据”,并对这些数据进行修补或移除以提高数据质量的过程[9-10]. 数据清洗是针对采集到数据库中的原始数据集进行的,是提升数据质量的关键环节. 评价数据质量的优劣有很多种维度,使用中通常都要结合具体的应用场景来选择合适的维度. 一般认为,完备性、一致性、及时性、有效性和完整性是评价数据质量最重要的5个维度,因此,在数据治理过程中通常都是针对这5个维度展开工作[11].
1)数据清洗的流程.
数据清洗的流程如图2[11]. 首先,根据业务需求,对待清洗的原始数据集进行初步分析,弄清数据集中各项数据的含义; 然后,结合数据标准和实际业务要求,从完备性、一致性、及时性、有效性和完整性等5个维度对数据进行检测清洗,补充缺失数据,删除重复数据,纠正错误数据,更新最新数据,同时记录数据清洗过程中发现的问题以及相应的处理情况; 最后,将数据清洗过程中发现的问题进行整理并生成数据质量报告,发送给数据生产单位进行整改; 同时,将清洗过的数据进行综合处理,存储到指定位置,为后续工作提供基础.
2)评价数据质量的五个重要维度.
表1对评价数据质量5个重要维度的检查内容及检查后输出的报告内容分别进行描述.
![图2 数据清洗流程示意图[11]](2020年增刊1/pic158.jpg)
图2 数据清洗流程示意图[11]

表1 评价数据质量的5个重要维度
3)数据清洗示例.
示例1:对不规范单位名称的标准化转换. 如单位名称(电教中心、网络中心、网管中心、信息办和信息化办)都代表信息化建设与管理办公室.需要根据数据标准,采用统一的名称来表示. 可以先建立一个数据字典,其中,键的取值范围是所有不同表示方式的集合.
{
“电教中心”=>” 信息化建设与管理办公室”,
“网络中心”=>” 信息化建设与管理办公室”,
“网管中心”=>” 信息化建设与管理办公室”,
“信息办”=>” 信息化建设与管理办公室”,
“信息化办”=>” 信息化建设与管理办公室”,
…
}
示例2:对特定数据格式的验证,如电子邮箱地址格式验证、身份证验证、学号验证和工作证号验证. 可结合数据标准使用正则表达式进行验证. 验证南开大学电子邮箱算法示例为:
function checkEmail($email)
{
if
(ereg(“/^[a-z]([a-z0-9]*[-_。]?[a-z0-9]+)*@([a-z0-9]*[-_]?[a-z0-9]+)+[。][a-z]{2,3}([。][a-z]{2})?$/i; ”,$email))
{
return true;
}
else
{
return false;
}
}
1.2.4 数据整理数据整理是指根据实际业务需求,为方便数据管理和数据交换所做的数据梳理工作. 一般情况下,可根据属性和用途将数据划分为原始数据层、主题数据层、统计分析数据层和应用数据层.
原始数据层,顾名思义,存储的是数据采集过程中从不同数据源采集而来的原始数据,该层数据同数据源数据保持一致,未做任何加工. 除原始数据层外,其他3个分层存储的数据均是在对原始数据层数据进行清洗后所整理的数据分层.
主题数据层是按照不同业务主题所划分的纵向分类层,该层由多个主题域组成,每个主题域均是由与该主题相关的所有数据组成的数据集. 如,高校数据的主题域可划分为学校主题、学生主题、教学主题、研究生主题、教职工主题、科研主题、财务主题、资产主题、办公主题、党建主题、宿管主题、图书馆主题和一卡通主题等.
统计分析数据层是用于对数据集中的各类数据进行专项统计分析的数据分层. 该分层中的统计数据是根据实际业务需求在线建模创建的. 如,高校的统计分析数据层包括学校基础数据统计、科研数据统计、财务数据统计和资产数据统计等.
应用数据层是面向具体业务应用划分的数据分层,该分层由不同应用的数据集组成,每个数据集都是单独为该应用提供的数据. 如,高校的应用数据层可包括办公OA系统数据集、教务系统数据集和科研系统数据集等.
1.2.5 数据交换数据交换是将符合源模式的数据转换为符合目标模式数据,该目标模式尽可能准确并且以与各种依赖性一致的方式反映源数据[12-15]. 一般情况下,数据交换是在共同遵循“数据标准”的前提下,通过数据视图或webservice等方式在不同系统间进行的.
1.2.6 数据更新数据生产单位收到数据清洗阶段生成的数据质量报告后,根据报告内容对存在的问题数据逐一进行审核修正,最后通过相应的业务系统或文件将数据源更新. 源数据质量得到提升后,整体数据质量就得到了提升,如此往复循环,整体数据质量就会越来越好,从而达到数据治理的目的.

期刊信息
深圳大学学报理工版
JOURNAL OF SHENZHEN UNIVERSITY SCIENCE AND ENGINEERING
(1984年创刊 双月刊)
主 管 深圳大学
主 办 深圳大学
编辑出版 深圳大学学报理工版编辑部
主 编 李清泉
国内发行 深圳市邮电局
国外发行 中国国际图书贸易集团有限公司(北京399信箱)
地 址 北京东黄城根北街16号
邮 编 100717
电 话 0755-26732266
0755-26538306
Email journal@szu.edu.cn
标准刊号 ISSN 1000-2618
CN 44-1401/N