基金项目:CERNET创新资助项目(NGII20190502, NGII20180203)
作者简介:折 波(1989—),西安交通大学工程师.研究方向:网络安全.E-mail: shebo@mail.xjtu.edu.cn
中文责编:晨 兮
作者简介:折 波(1989—),西安交通大学工程师.研究方向:网络安全.E-mail: shebo@mail.xjtu.edu.cn
中文责编:晨 兮
DOI: 10.3724/SP.J.1249.2020.99118
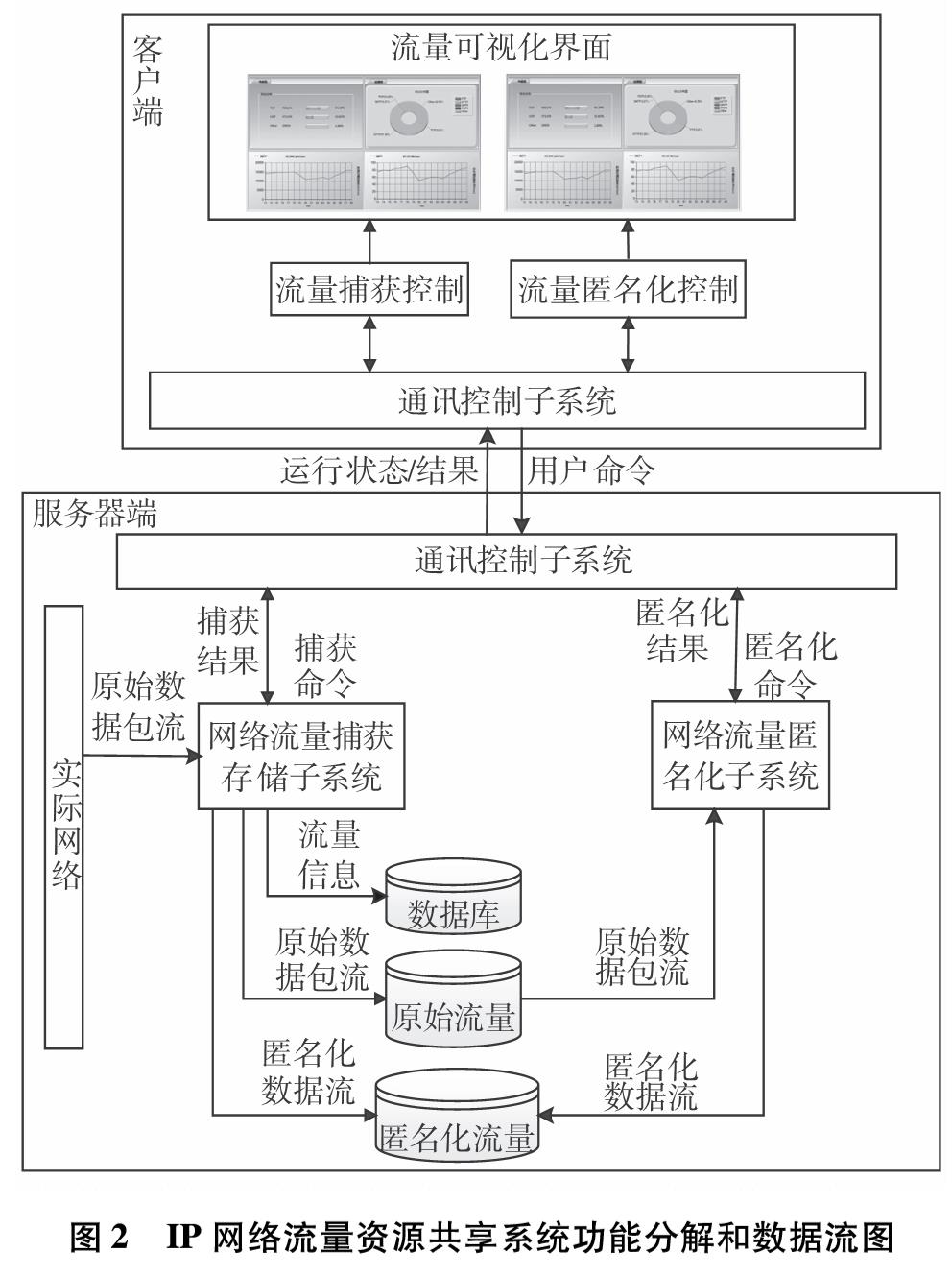
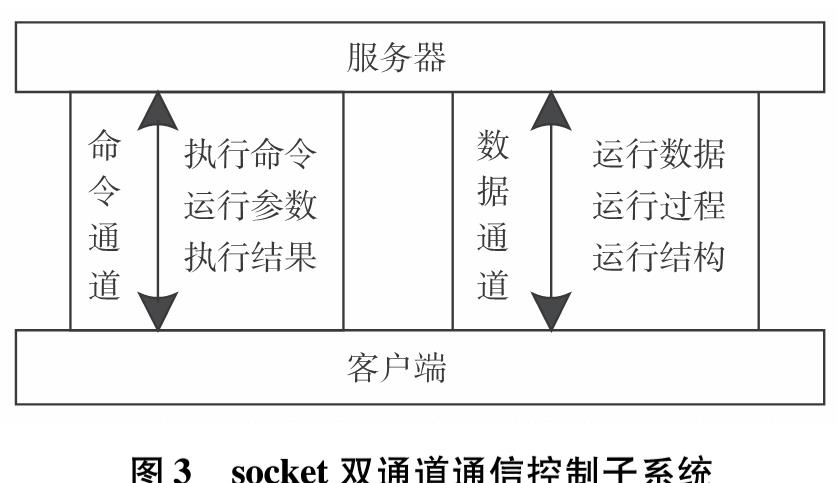
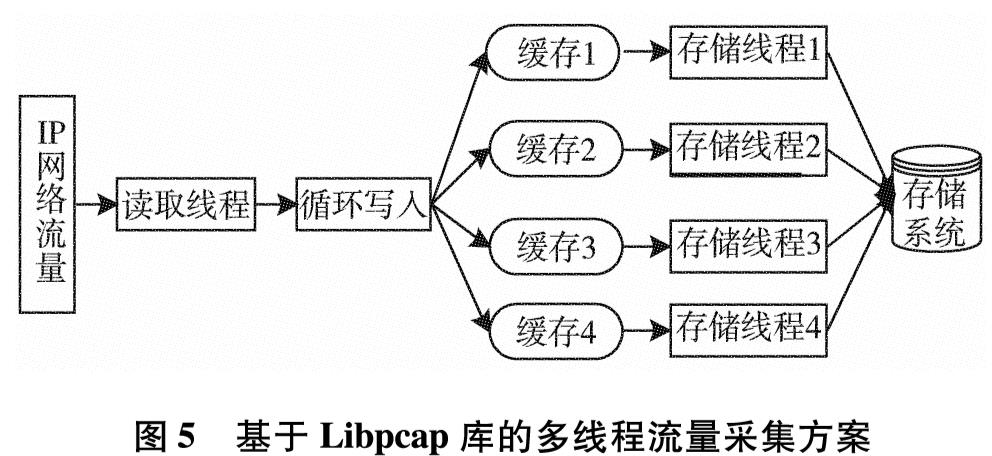
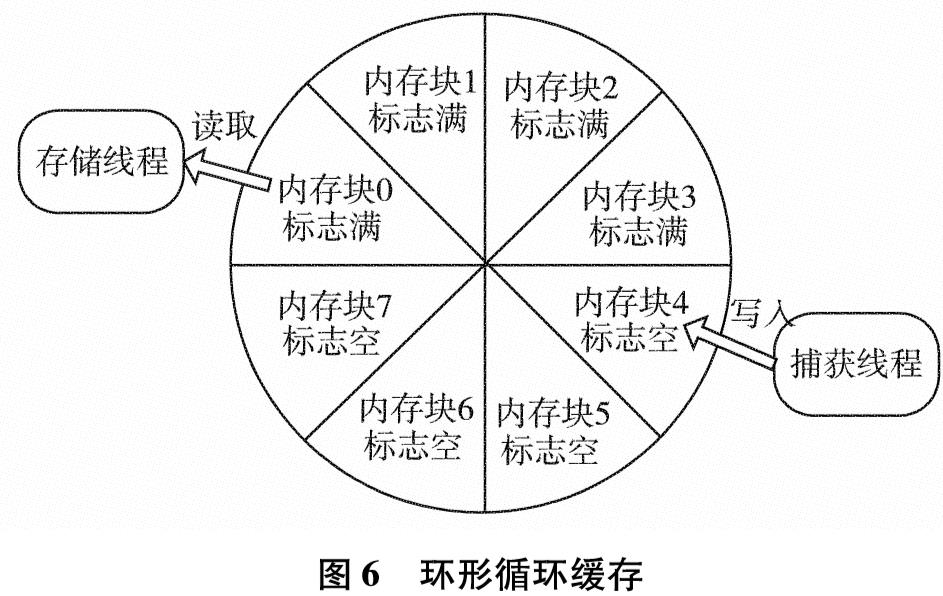
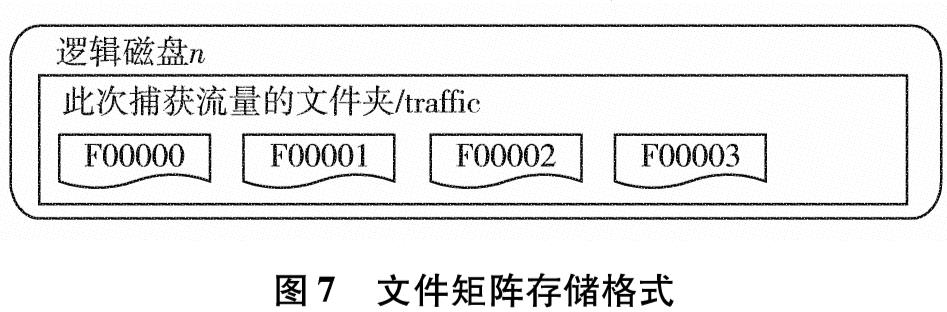
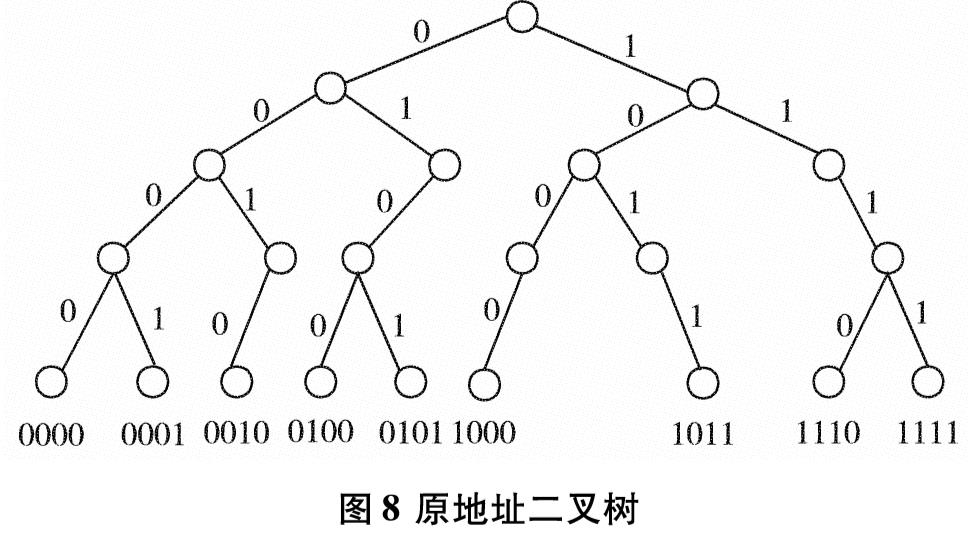
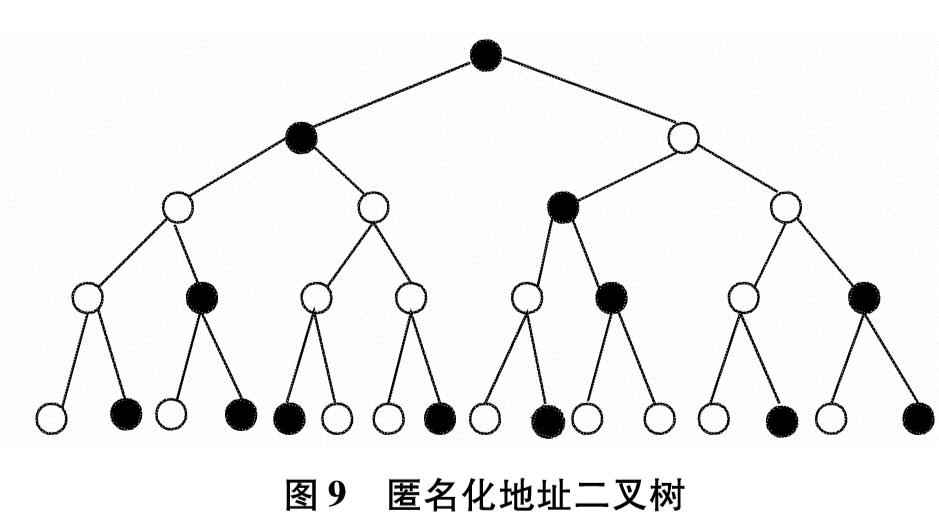
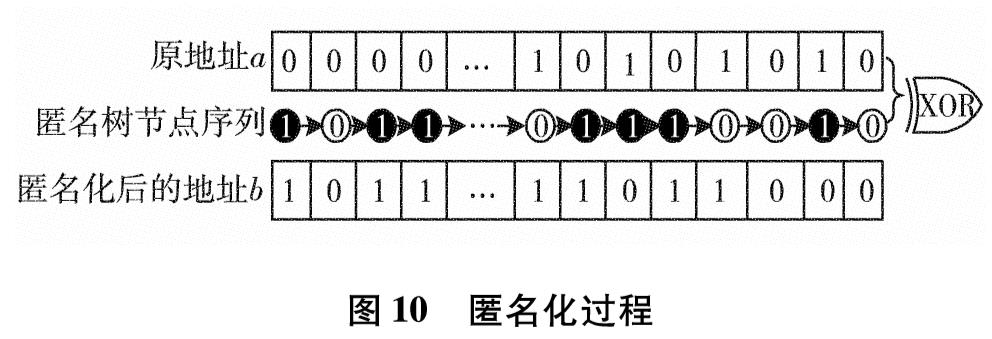
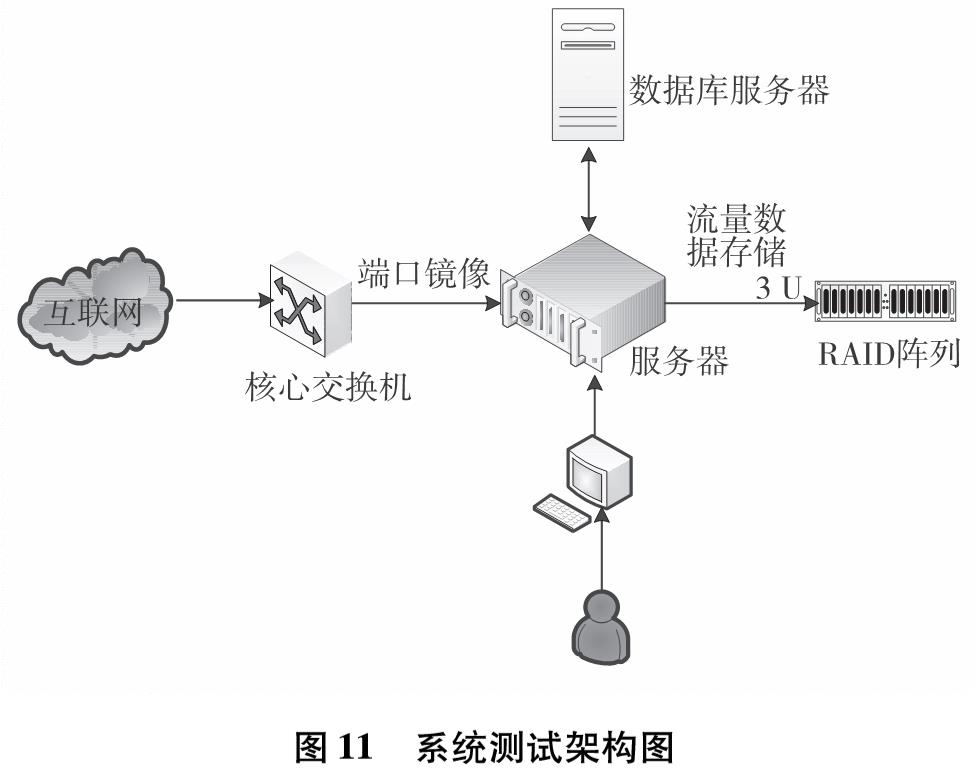
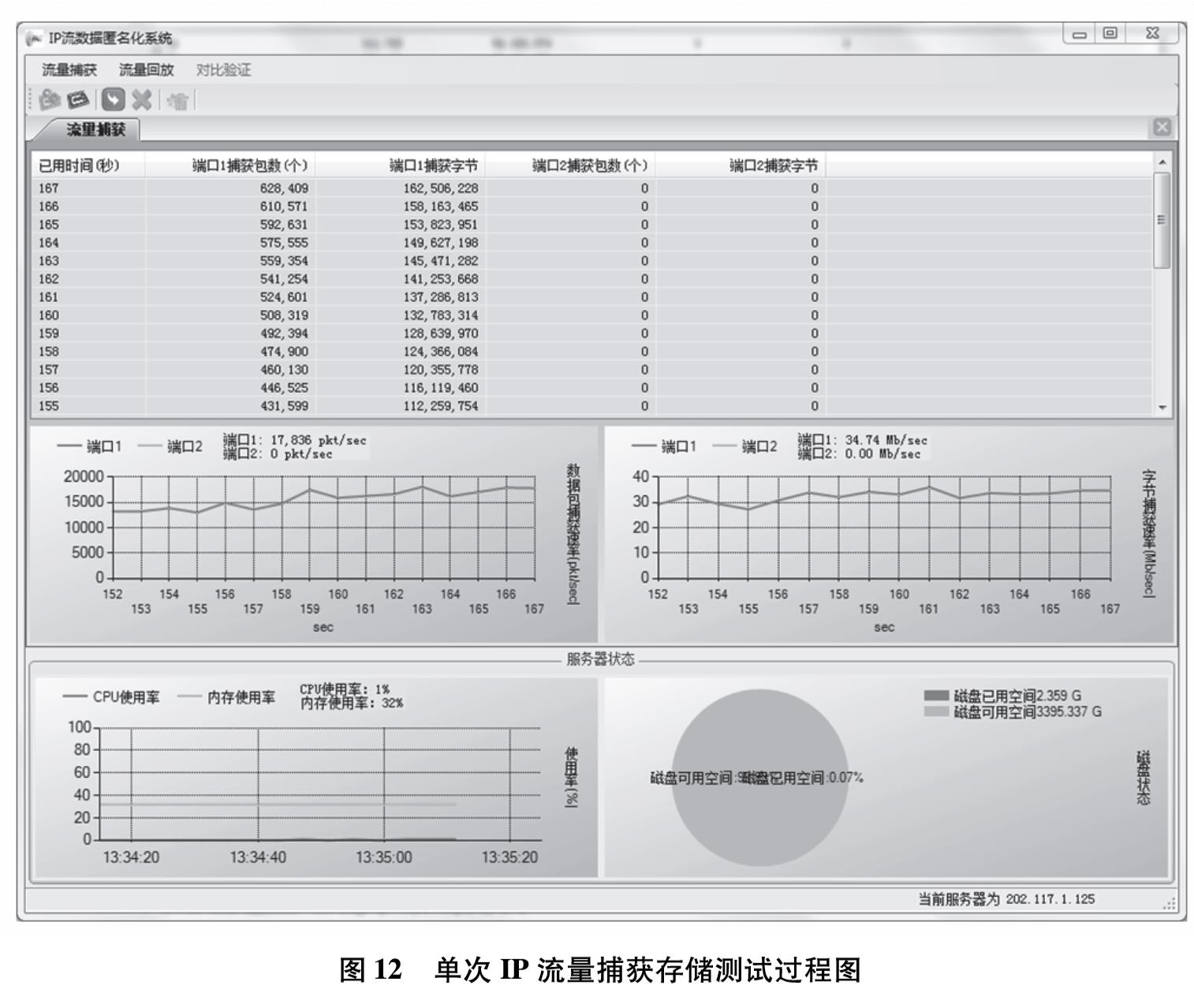
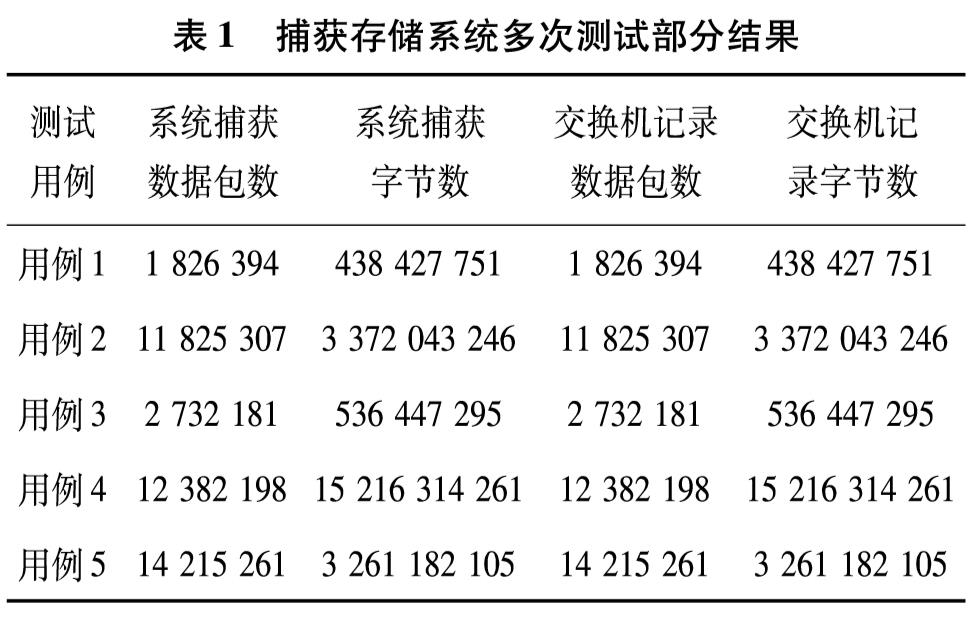
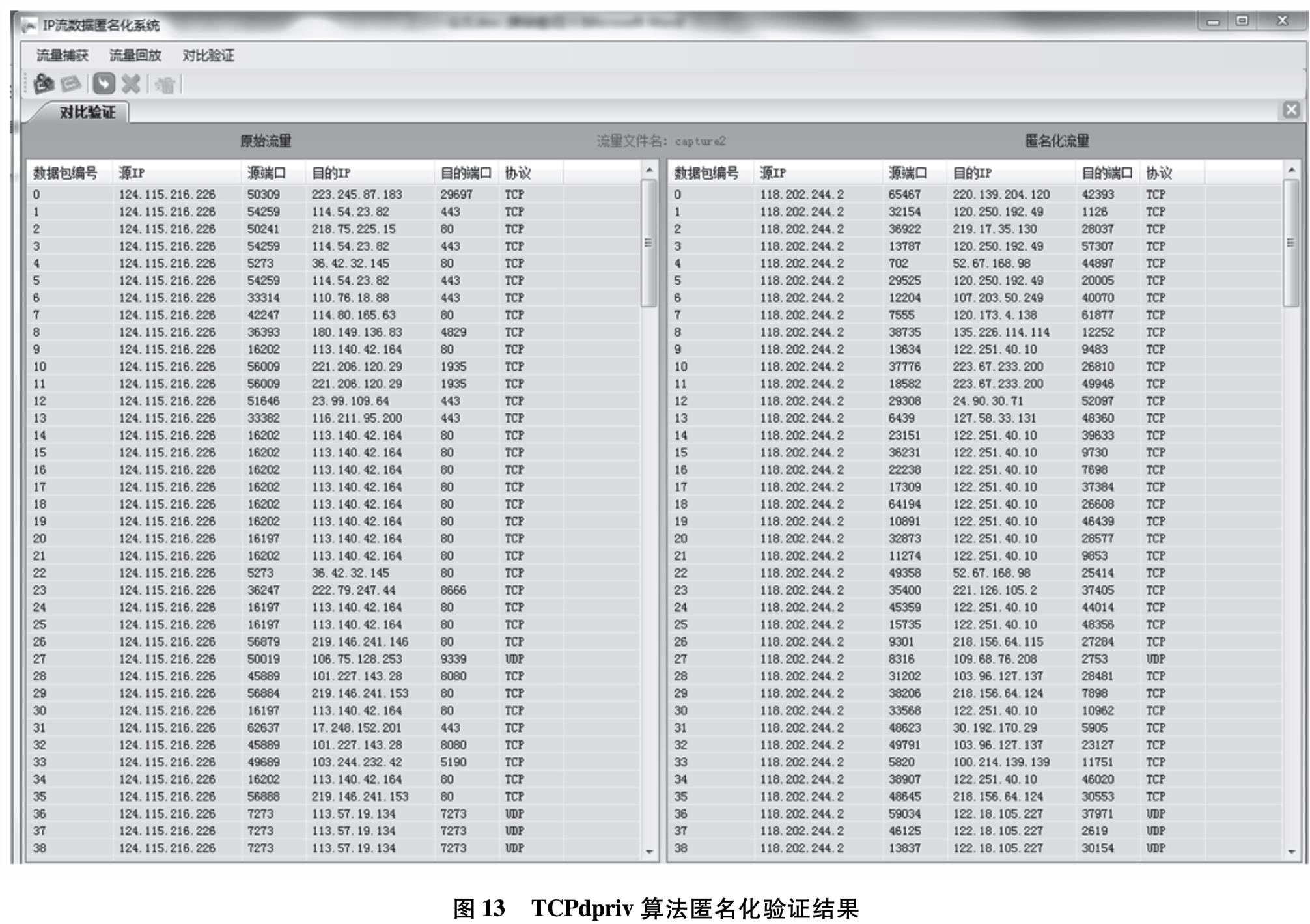
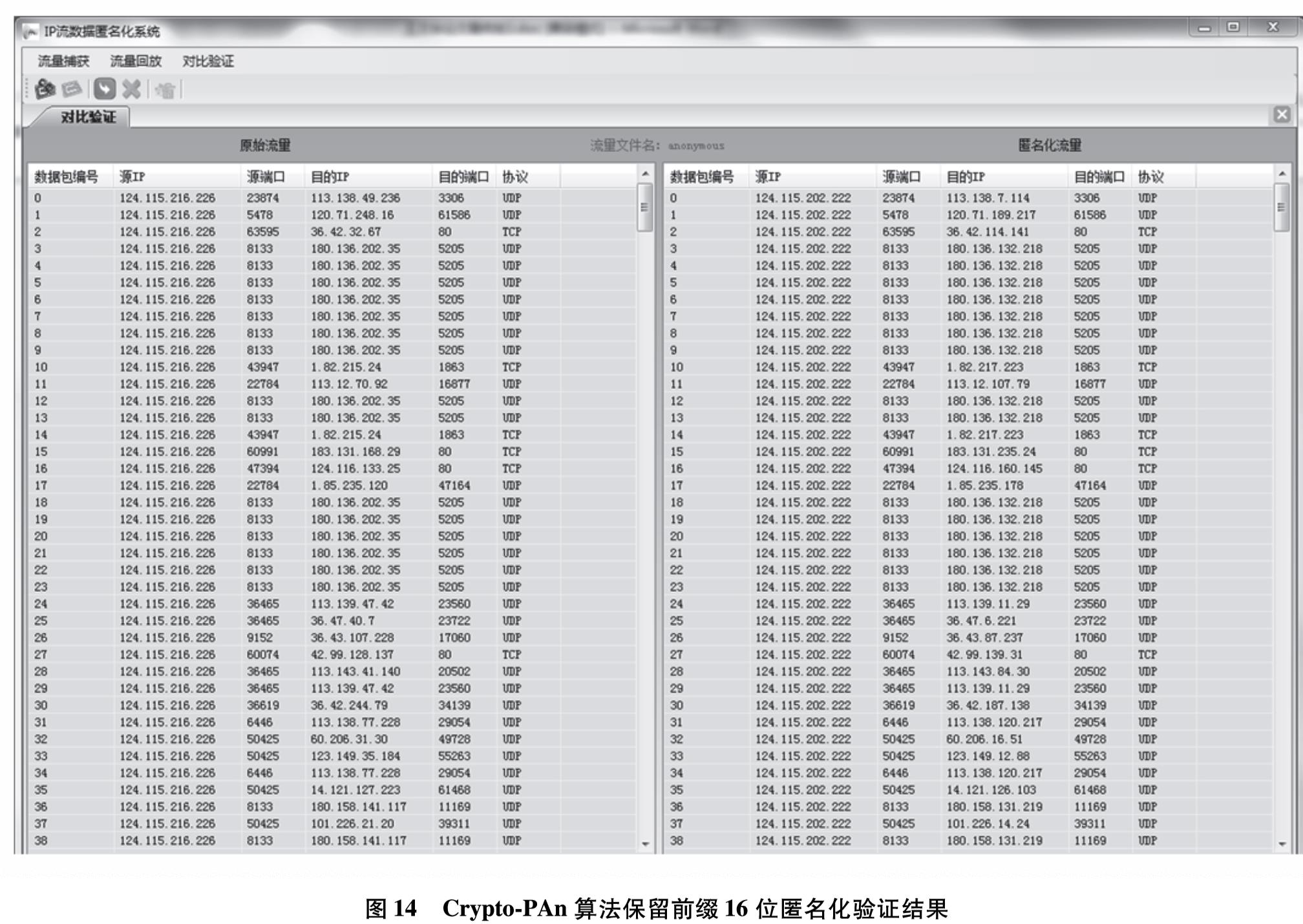
为改善目前网络基础研究领域对网络流量基础数据极度缺乏的现状,设计实现一套IP网络流量资源共享系统.系统使用了socket双通道的通信控制、Libpcap多线程网络流量捕获、环形循环缓存、文件矩阵网络流量存储、保留前缀的匿名化算法TCPdpriv以及Crypto-PAn流量匿名化等技术,设计了详细的测试方案针对系统各项功能和性能做了测试.测试结果表明,系统实现了千兆限速IP网络流量的捕获、存储、匿名化以及共享,为网络研究者对基础网络的研究以及网络设备厂商对设备的测试提供了基础数据.
In order to improve the current situation of the extremely lack of basic network traffic data in the field of network basic research, we design and implement a set of IP network traffic resource sharing system. We use technologies including socket dual-channel communication control, Libpcap multi-threaded network traffic capture, circular caching, file matrix network traffic storage, prefix-preserving anonymization algorithm TCPdpriv, and Crypto-PAn traffic anonymization. A detailed test plan is designed to test the functions and performance of the system. The test results show that the system has achieved the capture, storage, anonymization and sharing of gigabit speed-limited IP network traffic. The system can provide basic data for network researchers to study basic networks and network equipment manufacturers to test equipment.