基金项目:国家自然科学基金资助项目(91546121); 国家社会科学基金资助项目(16ZDA055)
作者简介:赵朋亚(1995—),北京邮电大学硕士研究生.研究方向:网络表征学习、欺诈检测.
中文责编:英 子; 英文责编:木 柯
作者简介:赵朋亚(1995—),北京邮电大学硕士研究生.研究方向:网络表征学习、欺诈检测.
中文责编:英 子; 英文责编:木 柯
DOI: 10.3724/SP.J.1249.2020.05482
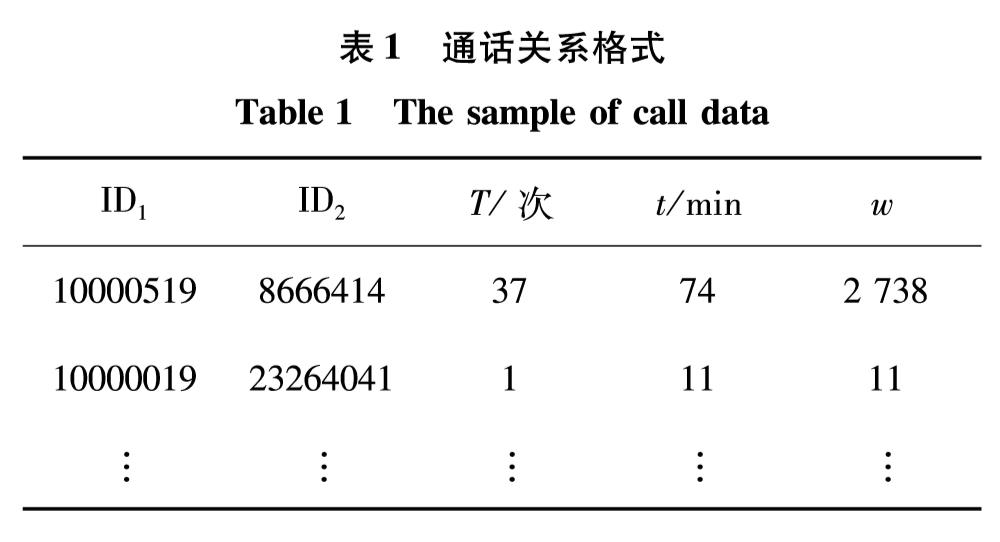
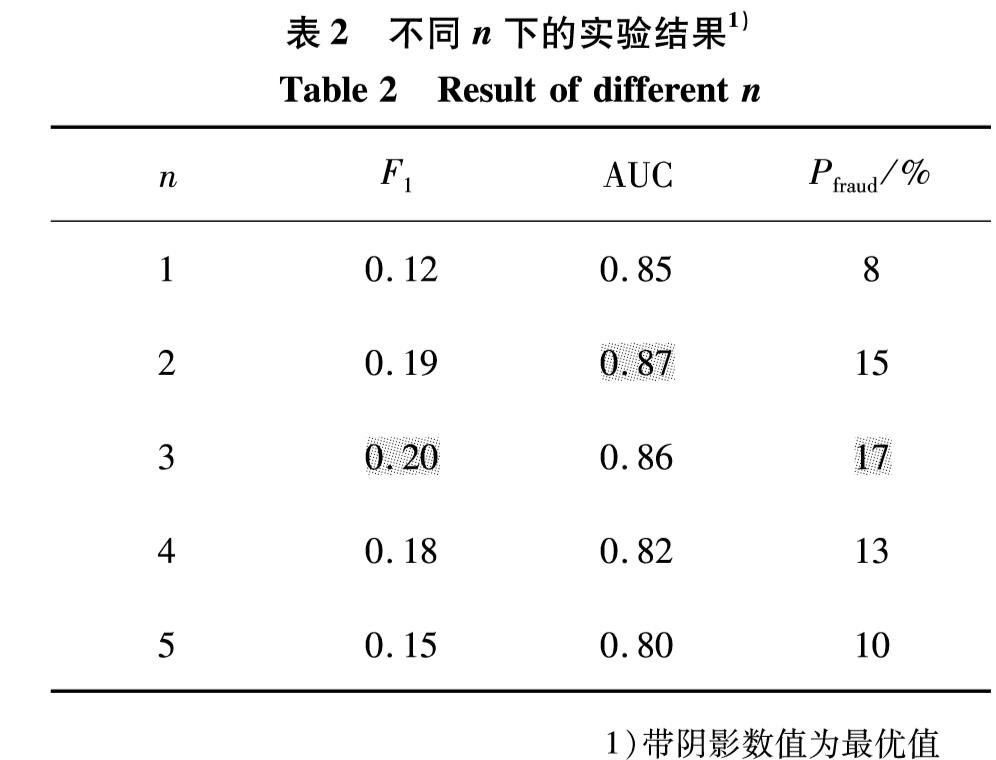
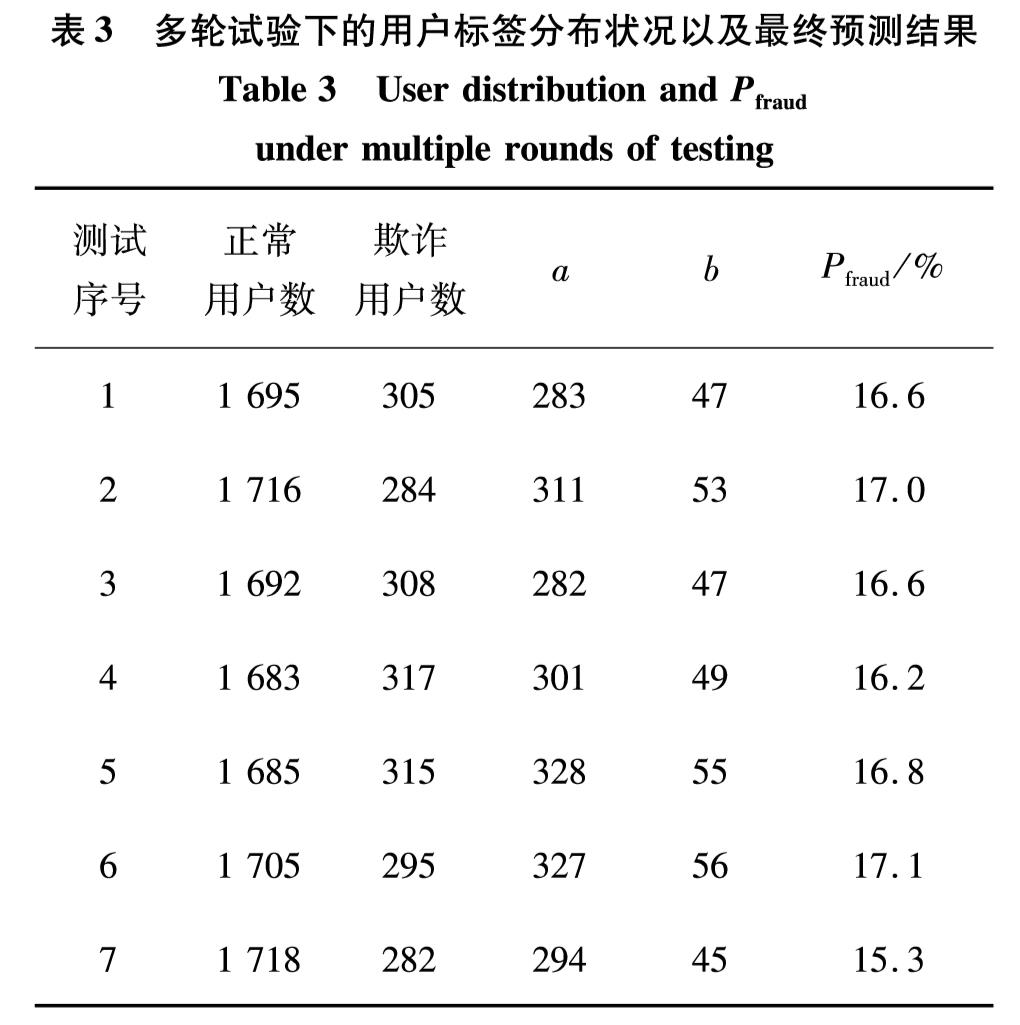
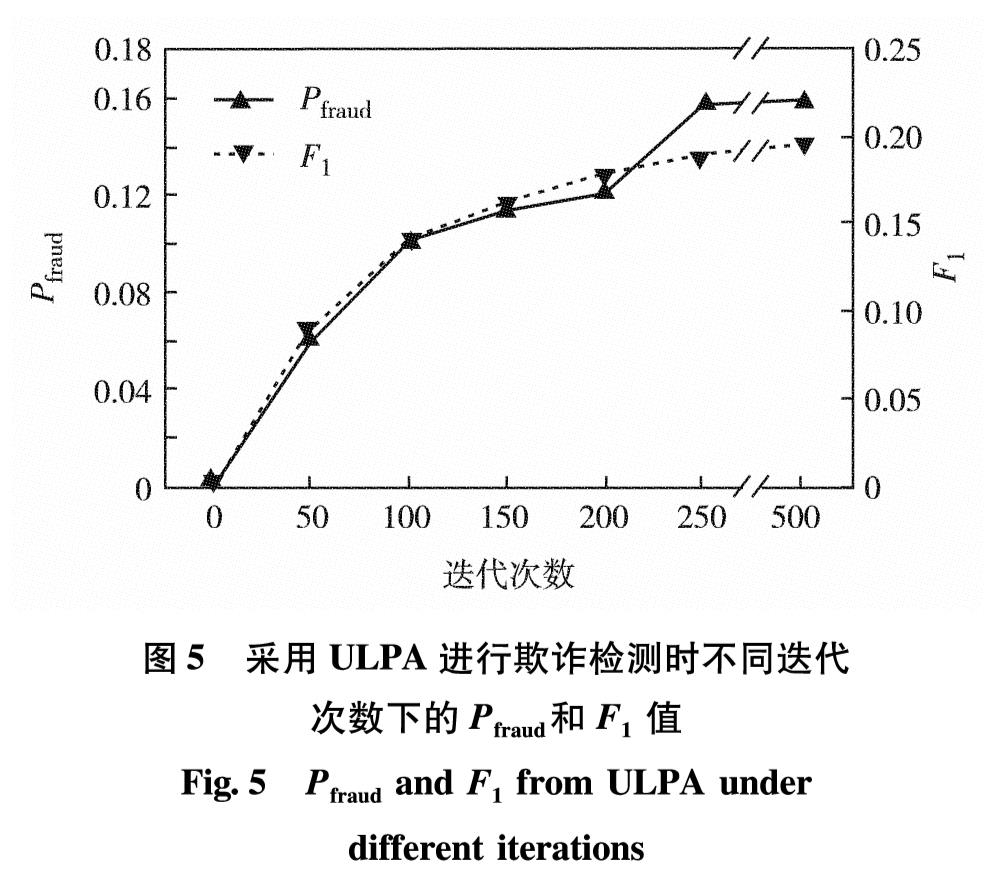
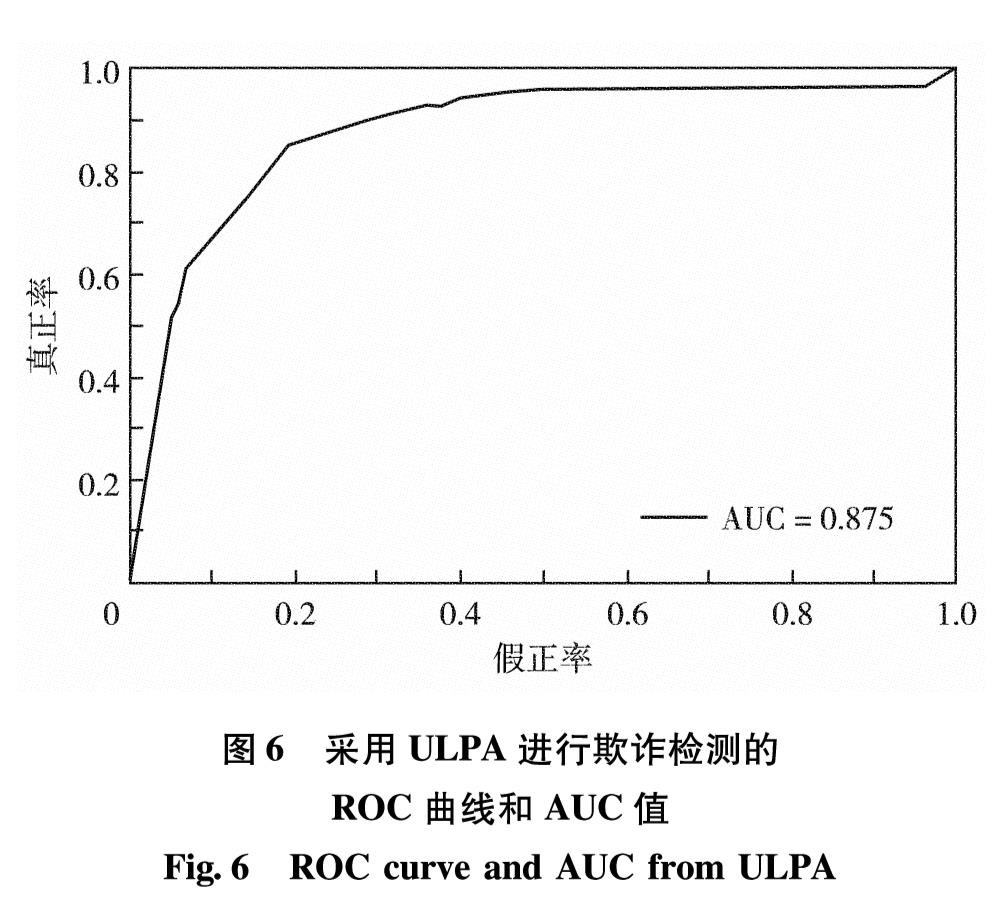
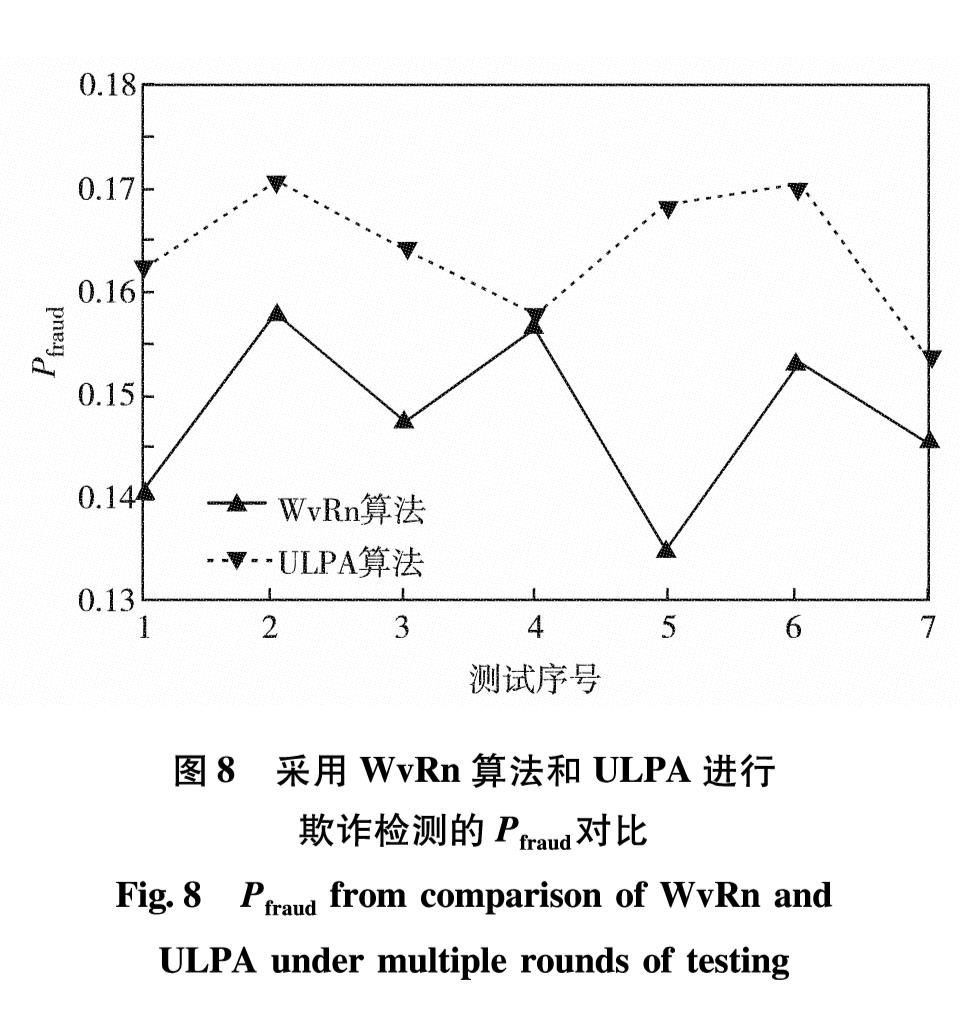
网络借贷领域中的欺诈检测是根据收集到的用户历史交易数据等信息,来判断该用户是欺诈用户还是正常用户.现有方法认为用户是独立存在的,忽略了用户之间的关联信息.考虑到目前欺诈逐渐成为群体行为,在欺诈网络内呈现出欺诈节点与非欺诈节点关联稀疏,而欺诈节点间关联紧密的现象,提出基于标签传播的协同分类欺诈检测方法.通过收集真实网上借贷公司的用户通话数据,构建用户之间的通话关联网络,利用标签传播算法扩散欺诈节点的标签信息,确定未知标签节点是否为欺诈用户.通过对权重进行幂操作,改进了标签传播算法中概率转移矩阵的初始化方法,使其适应欺诈场景下正负样本分布不平衡的现象.在有标签样本比例极低且训练样本分布不均衡的真实借贷数据集中进行了7次测试,采用所提算法检测到欺诈用户的精确率最高达17%,所得F1值与精确率都比经典的WvRn算法更优.
In the field of online lending, the key problem for fraud detection is how to judge whether the user is a fraudster or a normal user based on the collected historical transaction data of the user. At present, the representative research methods treat any user as an independent node and ignore the related information among users. Considering that the fraud is gradually becoming a group behavior, the relationships among fraud nodes and non-fraud nodes are sparse in social networks, and the relationships among fraud nodes are closely related, we propose a collective classification fraud detection method with label propagation. A call-records-based user association network is constructed based on the phone call records between users of online lending company, and we use the label propagation algorithm to spread the label information of fraud node to determine whether the unlabeled node is a fraudulent user. In addition, we improve the initialization method of transition probability matrixin label propagation algorithm by the operation of weights powering to avoid the performance degradation of label propagation algorithm caused by the unbalanced distribution of fraud data. Finally, the validation experiment is conducted in a real loan data set with a very low proportion of labeled samples and unbalanced training sample distribution. By using the proposed method in this article, the accuracy rate of fraud user detection reaches 17%, and the F1 value and accuracy rate are both better than those of the classic WvRn algorithm.