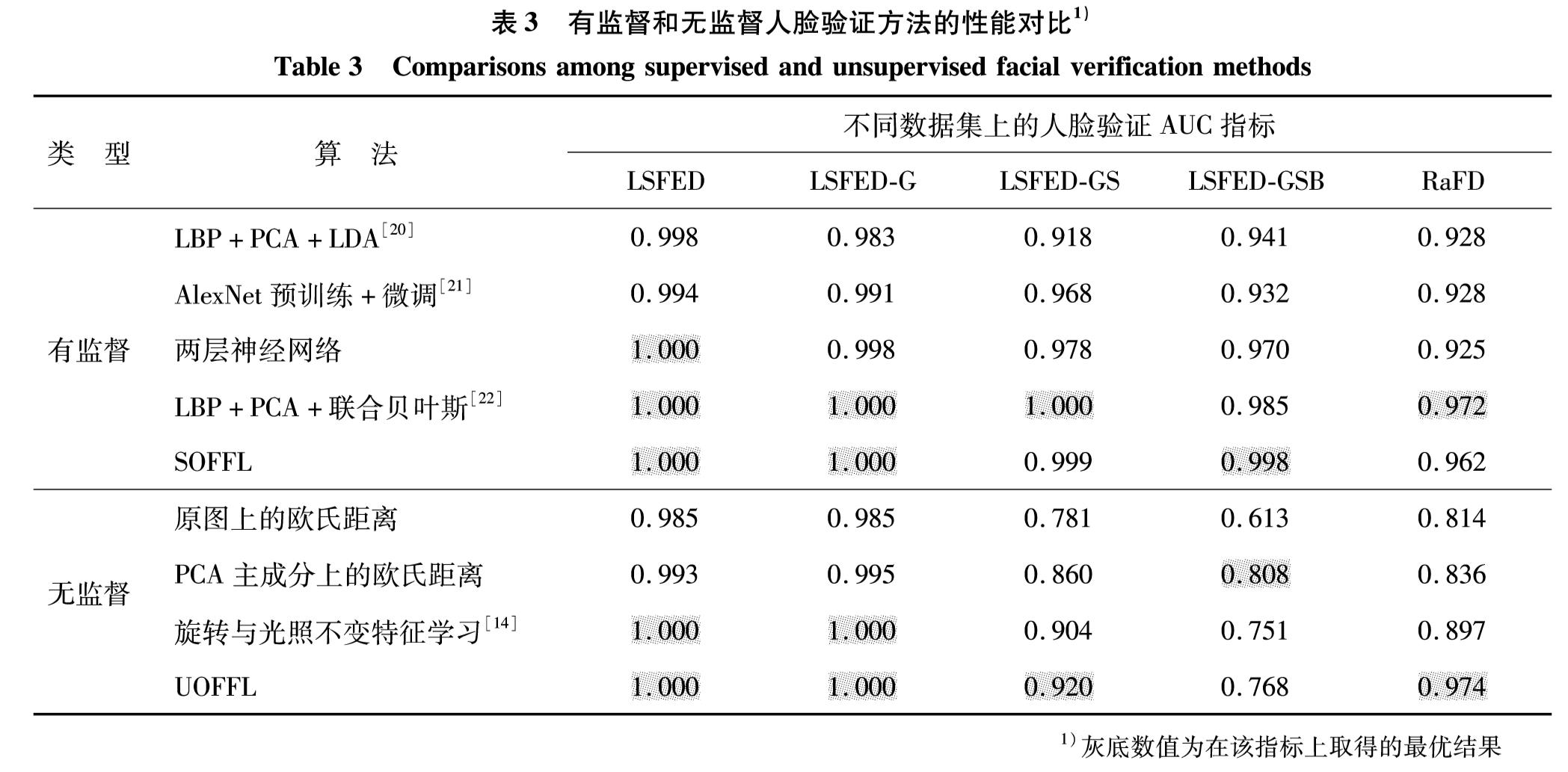
2.1 深度神经网络结构
为克服SUFFL算法训练数据要求高的缺点,本研究提出的UOFFL算法将针对Z的L2判别损失替换为相关性最小化损失,来缓解对中性脸Z的依赖.由于新损失是无监督的,故算法仅用二元组(X, y)进行训练,可视为SOFFL算法的无监督版本.图1和图2分别为SOFFL算法和UOFFL算法的网络结构.如图1,SOFFL算法所用的L2损失与监督信号是图像,采用了一个36层的卷积-反卷积-卷积-反卷积网络进行原图-中性脸-重构图的变换,网络的第18层输出中性人脸图像 Z^.UOFFL算法则是将中性人脸图像 Z^舍去,替换为一维的身份特征h,如图2.因此,SOFFL算法实现了用一个18层的卷积-反卷积神经网络替代原先的36层网络,网络层数和可训练参数数量减半.
图1 SOFFL的网络结构[1]
Fig.1 The network architectures of SOFFL[1]
图2 UOFFL的网络结构
Fig.2 The network architectures of UOFFL
在图2中, lrec为重构损失; lcls为分类损失; lcorr为相关性最小化损失.假设算法的已对齐人脸图像中仅存在身份和表情两种变化,则在前向传播中,卷积层将人脸图像编码为身份和表情特征,而反卷积层从特征中重构输入的人脸图像.
记含有表情的人脸图像为X,h和y^logit分别为身份和表情特征,二者组成卷积-反卷积网络的中间层激活为
(h, y^logit)=fθf(X)(5)
则网络的前向传播为
X ^=gθg(h, y^logit)(6)
其中,X ^为重构的人脸图像; fθf()和gθg()为卷积层与反卷积层形式化定义函数, θf和θg分别为其内含的可训练参数,即神经网络的训练对象.
记预测概率 y^=(y^1, y^2, …, y^C )T在对数空间中的点为 y^logit=(y^logit1, y^logit2, …, y^logitC )T, 则通过标准softmax归一化函数计得预测概率为
y^i=(exp(y^logiti))/(∑Cj=1exp(y^logitj)), i=1,2,…,C(7)
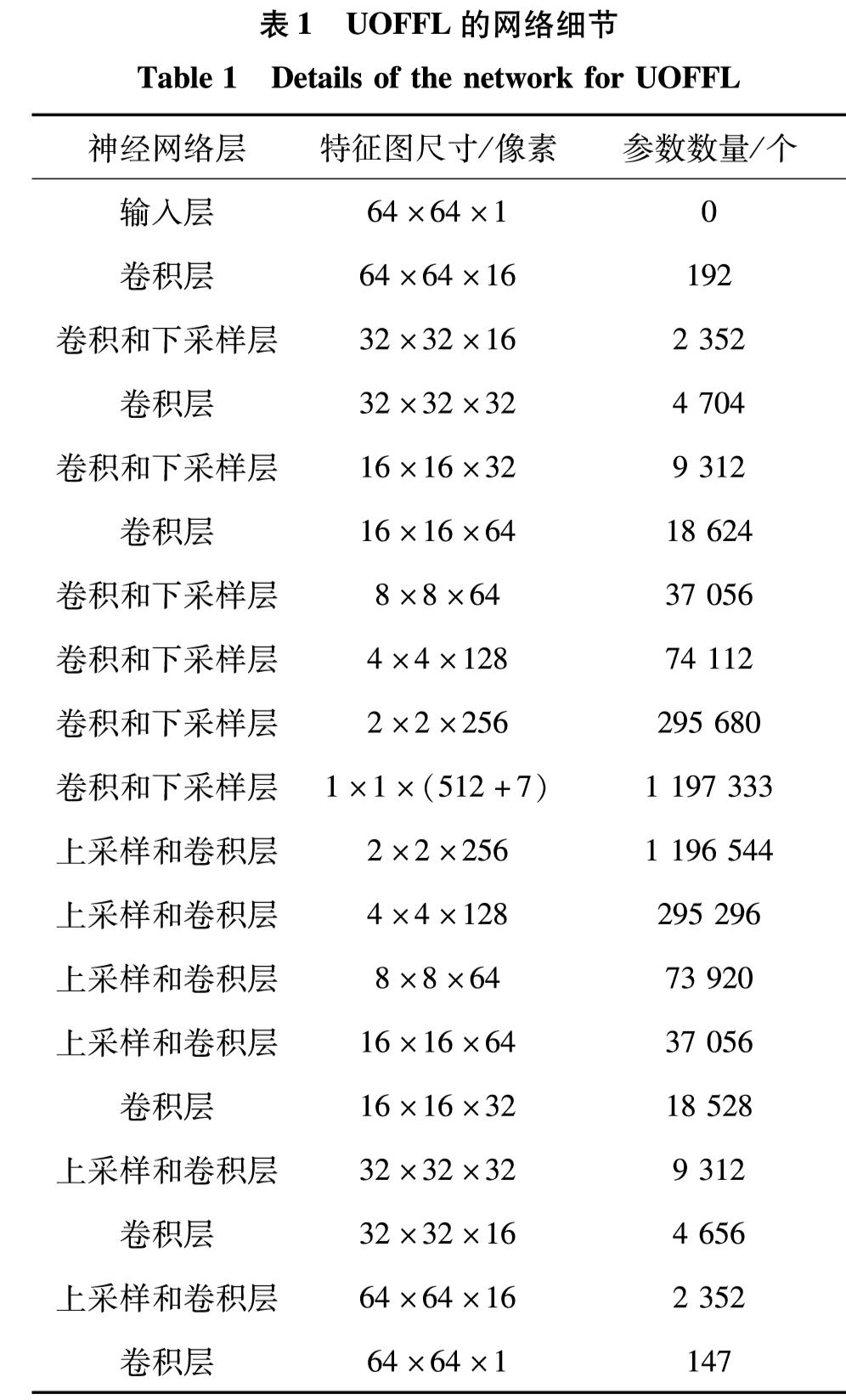
本研究参考VGG网络的设计思路,采用若干3×3卷积层后附一个下采样层组成的基础结构,再由若干基础结构构成网络.表1展示了UOFFL网络的层类型、层激活个数和层参数个数等细节,整个网络是由一个卷积部分和一个反卷积部分组成,其中卷积部分包含6个VGG基础结构,将尺寸为64×64×1像素的输入图像变换为1×1×519像素的全局向量形式特征; 而反卷积部分也包含6个VGG基础结构,其中后置下采样层替换为前置上采样层.反卷积部分将1×1×519像素的特征变换为64×64×1像素的图像.当输入尺寸、中间特征个数和输出尺寸确定时,表1中的细节可按VGG网络的基本规则生成.
表1 UOFFL的网络细节
Table 1 Details of the network for UOFFL
使用批归一化(batch normalization, BN)、激活函数tanh()和平均池化下采样法来确保网络激活的是标准正态分布.归一化激活分布不仅可加速训练还可简化相关性最小化损失中的皮尔逊相关系数(Pearson correlation coefficient, PCC)的计算.每个卷积层使用BN归一化和tanh()激活.整个网络共包括了18个卷积层,不含任何全连接层,网络共有约328万个可训练参数,网络的规模远比一些常见网络小,但已足够达到提取正交特征、重构原始人脸的要求.
2.2 损失函数
根据图2,网络在训练中使用了重构损失lrec、分类损失lcls与相关性最小化损失lcorr.首先讨论lcorr,从协方差对齐的角度出发,需将式(2)对齐到0矩阵,以缩小各特征维度之间的两两线性相关性.从协方差最小化的角度(式(3)和式(4))出发,需额外限制特征的中心,即单一特征随机变量的期望值为0.如果采用传统的二阶统计量调整中的协方差最小化方法[10-13],来降低特征h与y^logit间相关性,会导致平凡解,即神经网络将学得较小的参数,从而使激活较小,进一步使激活函数tanh()总是工作在其线性区域,最终降低网络的非线性拟合能力,减缓训练,导致无法实现学习正交特征的初衷.为此,本研究将最小化协方差的方法改进为最小化特征h与特征y^logit的两两皮尔逊相关系数.随机变量a与b之间的皮尔逊相关系数为
ρ(a,b)=(E[(a-E(a))(b-E(b))])/(σ(a)σ(b))(8)
其中, E()和σ()分别为期望值与标准差函数.因此,两组随机向量 a=(a1, a2, …, am)T和 b=(b1, b2, …, bn)T之间的皮尔逊相关矩阵可定义为
ρ(a,b)=
[ρ(a1,b1)ρ(a1,b2)… ρ(a1,bm)
ρ(a2,b1)ρ(a2,b2)… ρ(a2,bm)
ρ(am,b1)ρ(am,b2)… ρ(am,bn)](9)
PCC是一种归一化的协方差,值域为[-1, 1],相比协方差矩阵,它对随机变量的尺度具有不变性.基于皮尔逊相关矩阵的相关性最小化损失为
lcorr==ρ(h, y^logit)=2F(10)
该损失在计算上等价于两两PCC的平方和,即
lcorr=∑mi=1∑nj=1[ρ(hi, y^logitj)]2(11)
其中, hi和y^logitj分别列举了 h=(h1, h2, …, hm)T和y^logit=(y^logit1, y^logit2, …, y^logitn )T中的所有特征.显然,最小化式(10)或式(11)可降低身份特征与表情特征之间的相关性.
计算lcorr需统计特征的均值与标准差,在实践中,由于深度神经网络往往采用随机梯度下降法训练,在少量样本上估计均值与标准差会引入不稳定的噪声.有学者采用滑动平均方法来获得稳定均值与标准差[16],而本研究采用另一种方法:若随机变量h与y^logit中的所有特征已是标准正态分布或某种已知分布,则可避免从数据中估计分布参数.因此,将BN归一化后的特征h用于式(10)的相关性计算,则E(h)=0、 σ(h)=1. 用中心化后的真实独热码 y-1/C取代式(10)中的 y^logit, 则E(y-1/C)=0, σ(y-1/C)=((C-1)/C2)1/2. 把上述常量E(h)、E(y-1/C)、σ(h)和σ(y-1/C)带入式(8)至式(10),可实现高效且精确的前向和反向计算.
此外,假设人脸图像X服从正态分布,训练采用一个L2损失来确保两组特征的组合(h, y^logit)信息完整,即
lrec==X-X ^=2F(12)
用分类损失lcls对比C维表情预测值 y^=(y^1, y^2, …, y^C)T与真实表情标签 y=(y1, y2, …, yC)T之间的差异
lcls=-∑Ci=1[yilg(y^i)+(1-yi)lg(1-y^i)](13)
假设人脸空间中仅有身份和表情两种变化,则分类损失lcls用于学习表情特征 y; 重构损失lrec用于确保信息完整性; 相关性最小化损失lcorr提升两组特征之间的独立性.总体损失为三者的加权和
ltotal=lrec+λ1lcls+λ2lcorr(14)
其中,非负权重λ1和λ2用于平衡3个分量的重要性.
![图1 SOFFL的网络结构[1]<br/>Fig.1 The network architectures of SOFFL[1]](2020年5期/pic33.jpg)