3.2 实验设置
对比算法包括原始的高维数据(baseline)和5种经典的无监督降维算法GOLPP[12]、PCAN[13]、DRRAL[17]、SPP[16]和全局和局部保持投影(global and local structure preserving projection, GLSPP)[23].其中,GOLPP和PCAN是只考虑数据分布局部信息的无监督降维算法; DRRAL和SPP是只考虑数据分布全局信息的无监督降维算法; GLSPP算法同时考虑了数据的全局信息和局部信息.在实验中,各种算法的参数设置如下:
GOLPP算法是对LPP[10]算法的改进.在LPP算法中,样本之间的相似性矩阵是预定义的,缺乏自适应能力,为此,GOLPP算法将相似性矩阵的学习与降维过程统一在一个框架中,相互指导.该方法需初始化邻接矩阵S,本实验采用文献[12]的初始化方式:
sij={e-(=xi-xj= 2)/t, xj∈Nk(xi)或 xi∈Nk(xj)
0, 其他(16)
其中, Nk(xi)为第i个样本的k近邻, k=1, 2,…, l-1, l为每个类别样本的数量; t为高斯核的参数,本实验取t=1/n∑ni=1=xi=2.
PCAN算法的主要思想是利用欧式距离指导概率近邻的学习,从而指导降维.在实验中,类簇的个数设置为数据集真实的类别个数,另外两个参数采用文献[13]中的设置.
DRRAL是基于自表示的无监督降维方法,算法分两个阶段:① 用文献[18]算法得到相似性矩阵,超参数 λ1=λ2=λ3=λ∈{0.1, 0.2, …, 1.0}, 簇的个数设为数据集的真实类别数; ② 将得到的相似性矩阵用于指导降维.
SPP算法是用稀疏表示学习重构系数关系,在低维数据中保持该重构系数关系.本实验采用文献[16]中的优化问题(16)进行稀疏重构.
GLSPP算法利用k-means聚类发现数据的标签信息,从全局角度和局部两个角度保持该信息.其中,用于平衡全局和局部信息的超参数β∈{0.01, 0.1, 1, 10, 100}. 本研究方法超参数集合α∈{0.001, 0.005, 0.010, 0.050, 0.100}, β∈{0.001, 0.01, 0.1, 1, 10, 100, 1 000}.
除baseline算法外,其他算法降维后的维数d∈{50, 60, …, 120}. 首先,在所得数据的低维表示数据集上执行k-means聚类,类的个数为真实类别数,类中心采用随机方法进行初始化.然后,计算k-means聚类得到的类标签向量与真实类标签向量的聚类精度(accuracy, ACC)和归一化互信息(normalized mutual information, NMI).为降低k-means聚类的随机性,此过程重复50次,再求平均值,以此来衡量降维结果的质量.
3.3 结果及分析
表2和表3分别展示了7种方法在5个数据集上所有维度d∈{50, 60, …, 120}中的最优ACC值和NMI值,以及对于对应的维度.
表2 7种方法在5个数据集上的聚类精度比较1)((-overx)±s)
Table 2 The results of clustering accuracy on all data sets((-overx)±s)%
表3 7种方法在5个数据集上的归一化互信息比较1)((-overx)±s)
Table 3 The results of normalized mutual information on all data sets((-overx)±s)%
由表2可见,与其他方法相比,本研究方法在5个数据集上的ACC值都有提升,升幅3.02%~8.20%.由表3可见,本研究方法的NMI值比其他方法在5个数据集上都有提升,升幅为0.01%~6.20%.这是由于本研究方法利用稀疏表示挖掘数据分布的全局信息,约束降维后的样本保持该信息,同时约束系数矩阵是凸组合,进而有概率近邻的含义,以此挖掘数据分布的局部信息,而且将数据分布的挖掘和降维统一到一个框架中,相互指导,自适应得到数据的低维表示.
3.4 参数敏感性分析
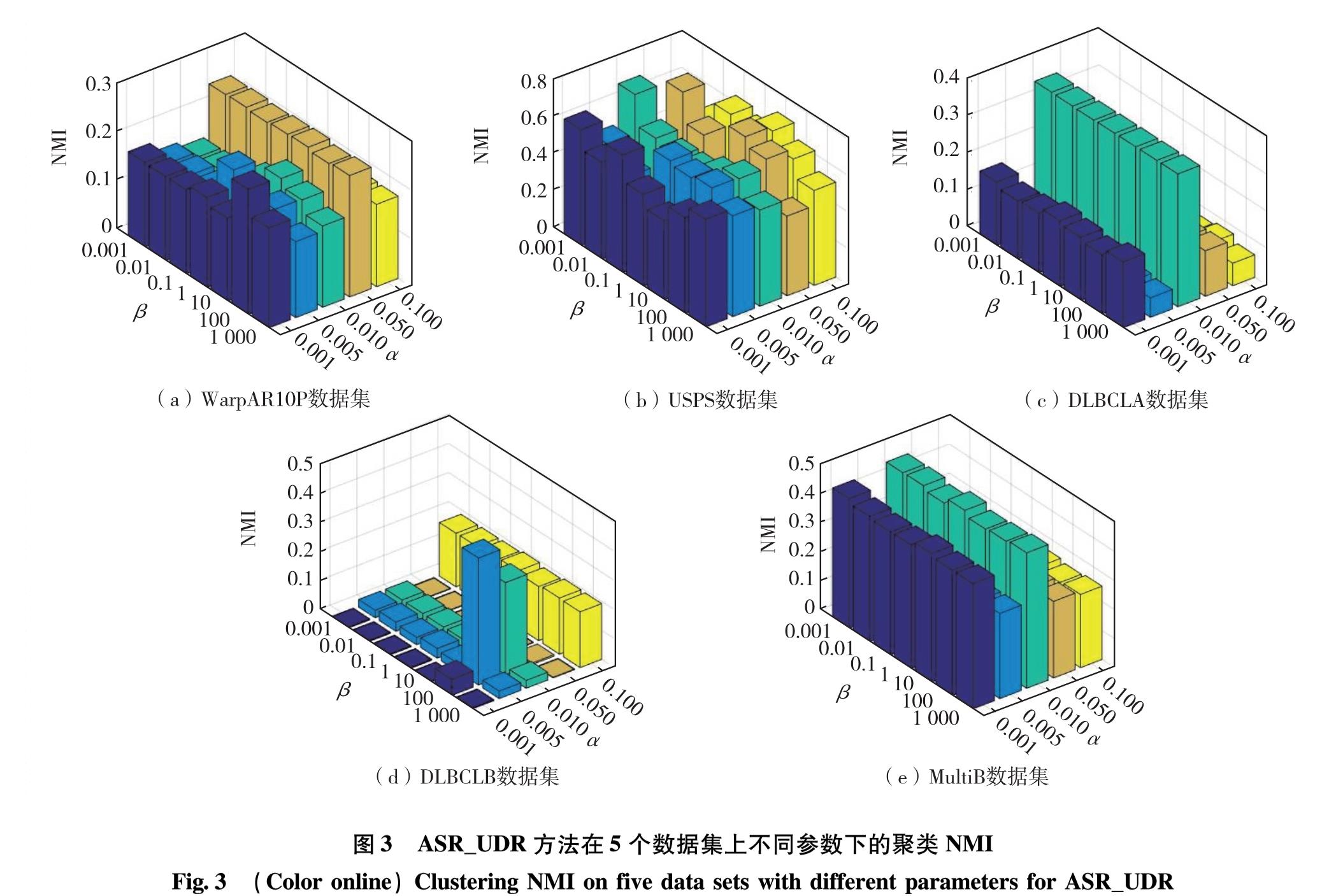
图2和图3分别展示了5个数据集在不同α和
图2 ASR_UDR方法在5个数据集上不同参数下的聚类ACC
Fig.2 (Color online)Clustering ACC on five data sets with different parameters for ASR_UDR
图3 ASR_UDR方法在5个数据集上不同参数下的聚类NMI
Fig.3 (Color online)Clustering NMI on five data sets with different parameters for ASR_UDR
β值下,采用ASR_UDR算法得到的聚类ACC和NMI值实验结果.由图2可见,ASR_UDR算法的ACC指标对参数α和β不是很敏感,且当α相同时,算法的ACC指标对β不敏感; 当β相同时,算法对α较为敏感.由图3可见,相比聚类ACC指标,ASR_UDR算法的NMI指标对α和β较敏感,且当α相同时,算法的NMI指标对β不敏感; 当β相同时,算法对α较为敏感.在少量参数组合下,算法可达到较高性能.