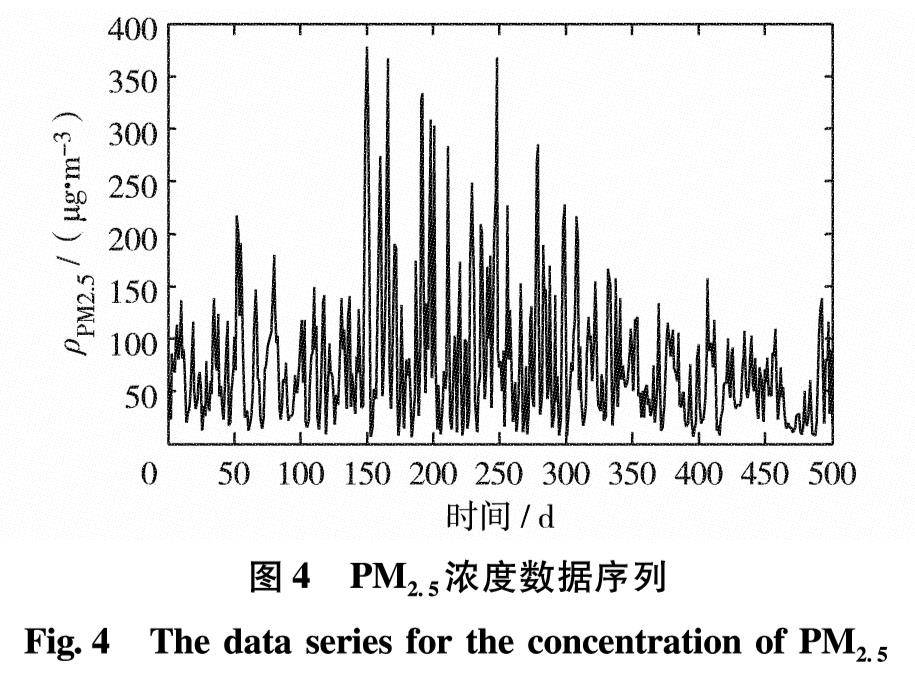
以2014-05-13至2015-09-25中国北京市PM2.5浓度数据(来自网站公开数据[15] )为例进行仿真分析.受供暖等环境因素影响,原始数据序列的波动较大,复杂程度较高.气象局记录数据间隔为1 h,且有部分缺失.数据处理时将以天(d)为单位对每天的PM2.5浓度做平均值处理,同时补充缺失值,共得到501个数据点[16],如图4.
图4 PM2.5浓度数据序列
Fig.4 The data series for the concentration of PM2.5
由图4可见,PM2.5浓度的原始时间序列呈现很强的非线性与非稳定性,序列的复杂程度较高.采用EMD分解方法处理原始PM2.5数据序列,以降低序列复杂程度,结果如图5.
图5 原始序列的EMD分解结果
Fig.5 The decomposition result of original series by EMD
针对每个IMF分量及趋势项,构建预测模型.选取前450个数据作为训练集,余下51个数据作为测试集,以均方根误差(root mean squared error, RMSE)及平均绝对误差(mean absolute error, MAE)为指标,衡量EMD-LSTM算法对时间序列的预测能力[17].
RMSE=((∑ni=1(Xreal,i-Xpre,i)2)/n)1/2(8)
MAE=(∑ni=1|Xreal,i-Xpre,i|)/n(9)
其中, Xreal,i为数据序列中第i个数据的真实值; Xpre,i为第i个数据的预测值; n为数据点个数.
排列熵作为一种检测时间序列随机性和动力学突变行为的方法,具有计算简单、抗噪声能力强等优点.因此,可以通过排列熵来衡量信号复杂度[18],排列熵值越大,其对应时间序列复杂程度越高.根据EMD分解得到各IMF分量的排列熵如图6.
图6 序列的排列熵
Fig.6 Permutation entropy of series
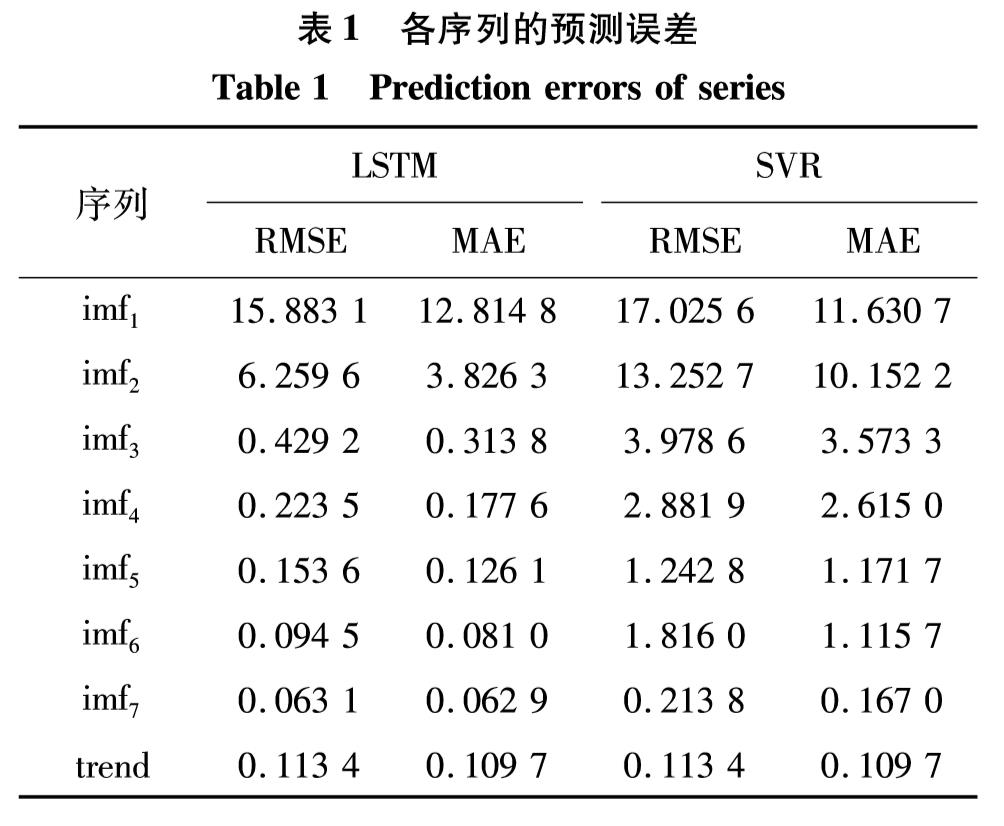
根据图5中EMD分解后的IMF序列及趋势项,分别构建LSTM预测模型.为对比验证,构建各自对应的SVR预测模型,选择RBF核函数及线性核函数进行时间序列预测,利用交叉验证方法确定核函数参数及惩罚参数.两种方法下各IMF分量及趋势项的RMSE及MAE计算结果如表1.
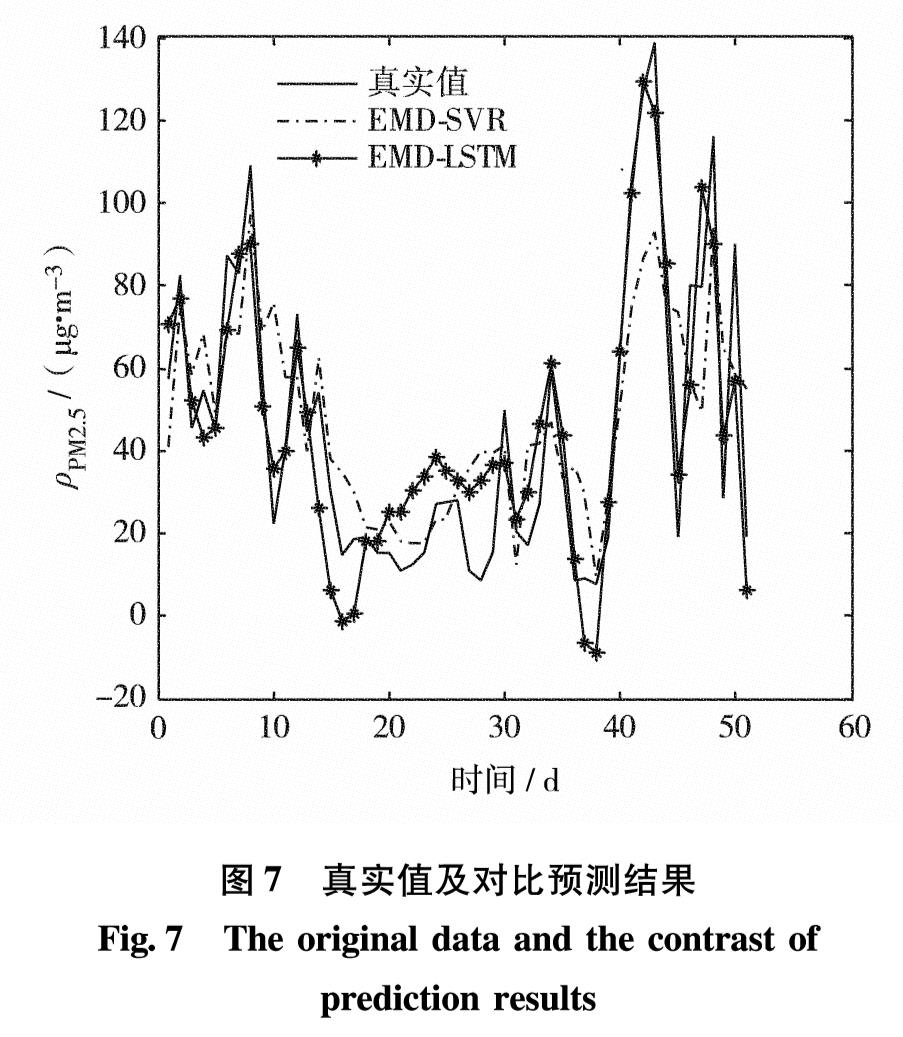
由表1及图6可见,随着IMF阶数的增加,各分量对应的排列熵逐渐降低,预测误差随之减小,证明了EMD算法对于降低IMF序列复杂程度的合理性.在表1中,由于趋势项的时间序列过于简单,因此,未进行区分对比预测.对IMF分量采用LSTM与SVR方法对比,结果表明,对于高阶IMF分量,随着时间序列复杂程度的降低,两种预测方法的差别逐渐降低,相比SVR预测模型,LSTM预测模型的优越性不断降低; 对于低阶IMF,LSTM表现出良好的预测效果,预测精度较SVR有明显提高.结合对EMD算法完备性的分析,分解得到的所有子序列重构之后,与原时间序列的误差量级为1×10-14.所以,将表1中各序列的预测结果相加,即可得到原始PM2.5数据序列的EMD-LSTM和EMD-SVR预测结果,如图7.可见,EMD-LSTM预测结果更贴近真实值.
表1 各序列的预测误差
Table 1 Prediction errors of series
图7 真实值及对比预测结果
Fig.7 The original data and the contrast of prediction results
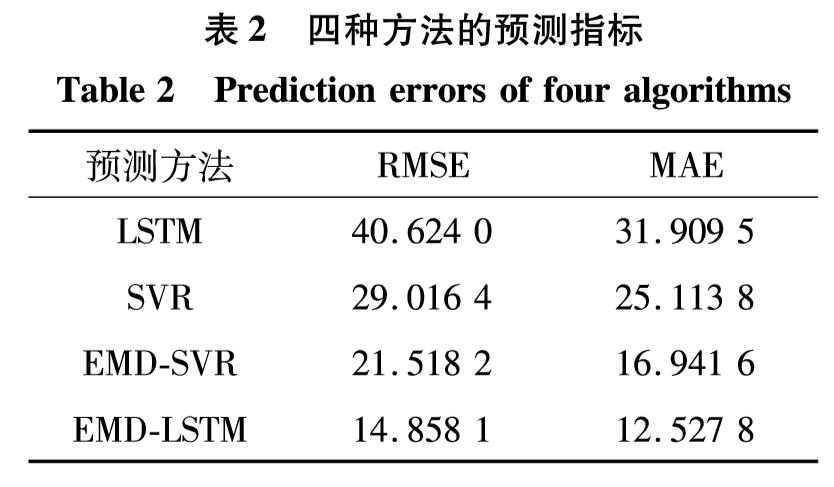
为验证EMD-LSTM算法的准确性,采用单个SVR模型及LSTM模型对原始PM2.5时间序列建立预测模型,并进行预测分析.将图7中得到的预测结果用数值形式进行分析,其RMSE及MAE指标如表2.
由表2可见,由于原始PM2.5数据序列的非线性及非平稳性,单一预测方法构建的预测模型不能对其进行准确预测,且由于序列的复杂程度较高,单一LSTM方法劣于SVR方法的预测效果; 在利用EMD算法对时间序列进行分解之后,一定程度上降低了原序列的复杂程度,此时,对分解得到的IMF分量及趋势项采用LSTM模型和SVR模型进行预测分析,其结果比单一LSTM及SVR模型均有显著提高,证明利用EMD方法对原始时间序列进行分解的可行性.相比EMD-SVR方法而言,采用EMD-LSTM方法预测结果的RMSE降低30.95%,MAE降低26.05%,预测精度得到明显提高.
表2 四种方法的预测指标
Table 2 Prediction errors of four algorithms
![图1 递归神经网络神经元[9]<br/>Fig.1 Structure of recurrent neurons[9]](2020年3期/pic41.jpg)