选取不同结构的人工网络和真实网络数据集对ASonlineVEM算法进行测试,并与半监督社区发现SuperNMF和ALISE算法比较.其中,主动节点标记使用的约束对先验比例RP为网络节点对的百分比; 网络节点对为n(n-1)/2, n为网络节点数.
使用如式(7)的标准化互信息[17](normalized mutual information, NMI)来衡量算法准确性.它可较好地评估基准标签与计算得到的标签之间的相互关系和吻合程度,常用来评价网络结构发现的质量.NMI值越接近1,表示算法聚类准确度越高.
NMI(X,Y)=(2I(X; Y))/(H(X)+H(Y))(7)
其中, X是计算结果; Y是真实结果; I(X; Y)=∑x∑yp(x,y)lg(p(x,y))/(p(x)p(y)); H(X)=-∑x[p(x)lg p(x)]; H(Y)=-∑yp(y)lg p(y); p(x)和p(y)分别为x和y的概率分布; p(x, y)为x和y的联合概率分布.
算法使用Matlab 2014软件在Intel CoreTM i5-6200U CPU,8 Gbyte内存的Windows 7(64 bit)计算机上运行.考虑到算法每次运行都存在差异性,取5次结果的均值作为实验结果.
基准网络 Girvan-Newman(GN)网络中,顶点与社团外顶点连边数的均值Zout决定社区结构的清晰程度, Zout越大,网络结构越复杂.图1分别为Zout=8和Zout=9时3种算法的NMI结果对比.可见,ASonlineVEM算法准确率明显高于其他网络,尤其当Zout=9时, RP=1.6%, ASonlineVEM算法准确率为0.92,ALISE算法仅0.33.随着Zout增加,对比算法准确率明显下降,ASonlineVEM准确率较高,说明后者能准确发现更复杂的网络结构.
图1 三种算法在GN网络上的NMI对比结果
Fig.1 NMI comparison results of three algorithms on GN networks
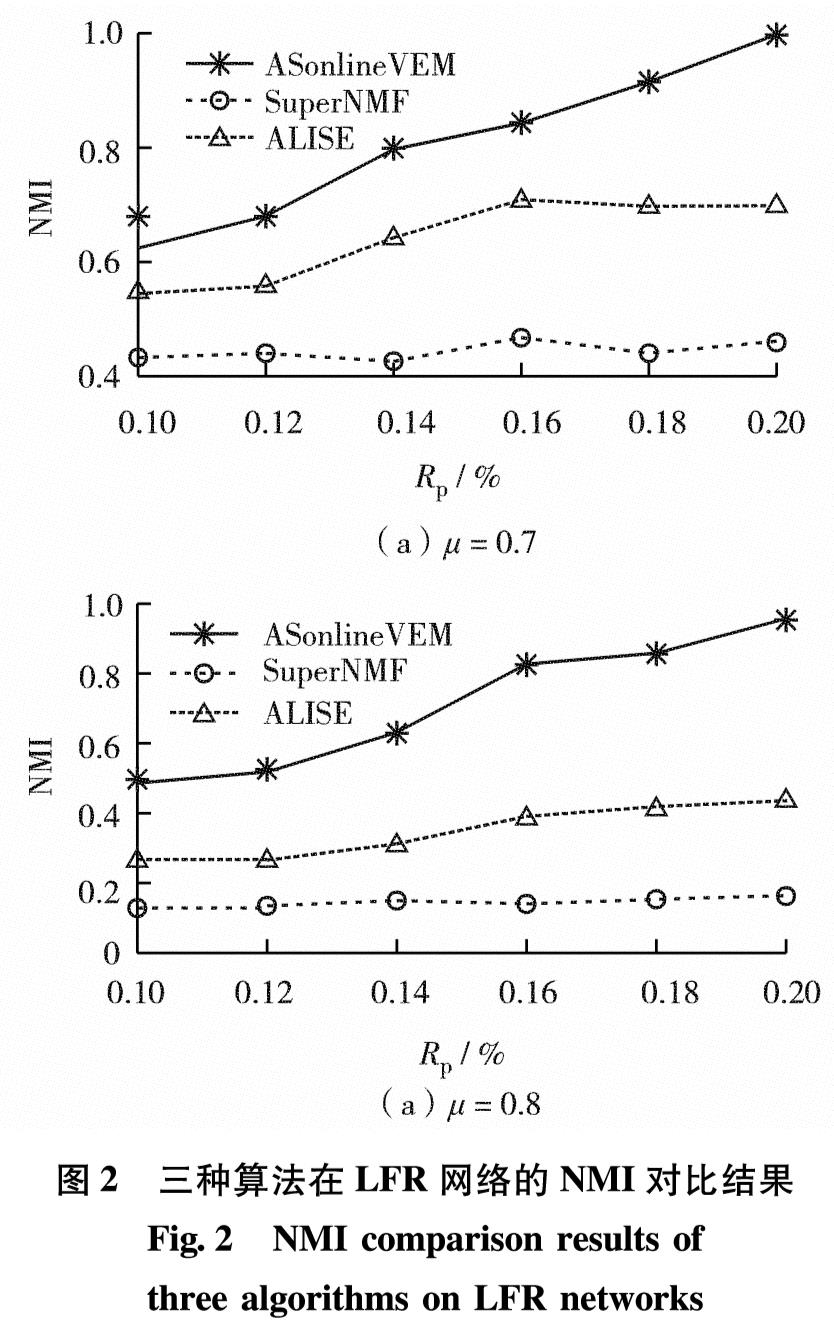
图2 三种算法在LFR网络的NMI对比结果
Fig.2 NMI comparison results of three algorithms on LFR networks
Lancichinetti-Fortunato-Radicchi(LFR)基准网络结构比GN网络的更复杂.设网络节点数分别为1 000,最小和最大社区节点数分别为20和100,节点度分布参数为2,社区大小分布参数为1,混合参数μ决定了发现网络结构的难易程度,设μ为0.7和0.8.图2为在LFR基准网络上3种算法的NMI结果.由图2可见,ASonlineVEM算法的的准确率明显高于对比的半监督社区发现算法.综上可见,在具有社区结构的基准网络上,ASonlineVEM算法的社区发现准确率要高于对比算法,尤其在网络结构不清晰时更能体现算法的优势.
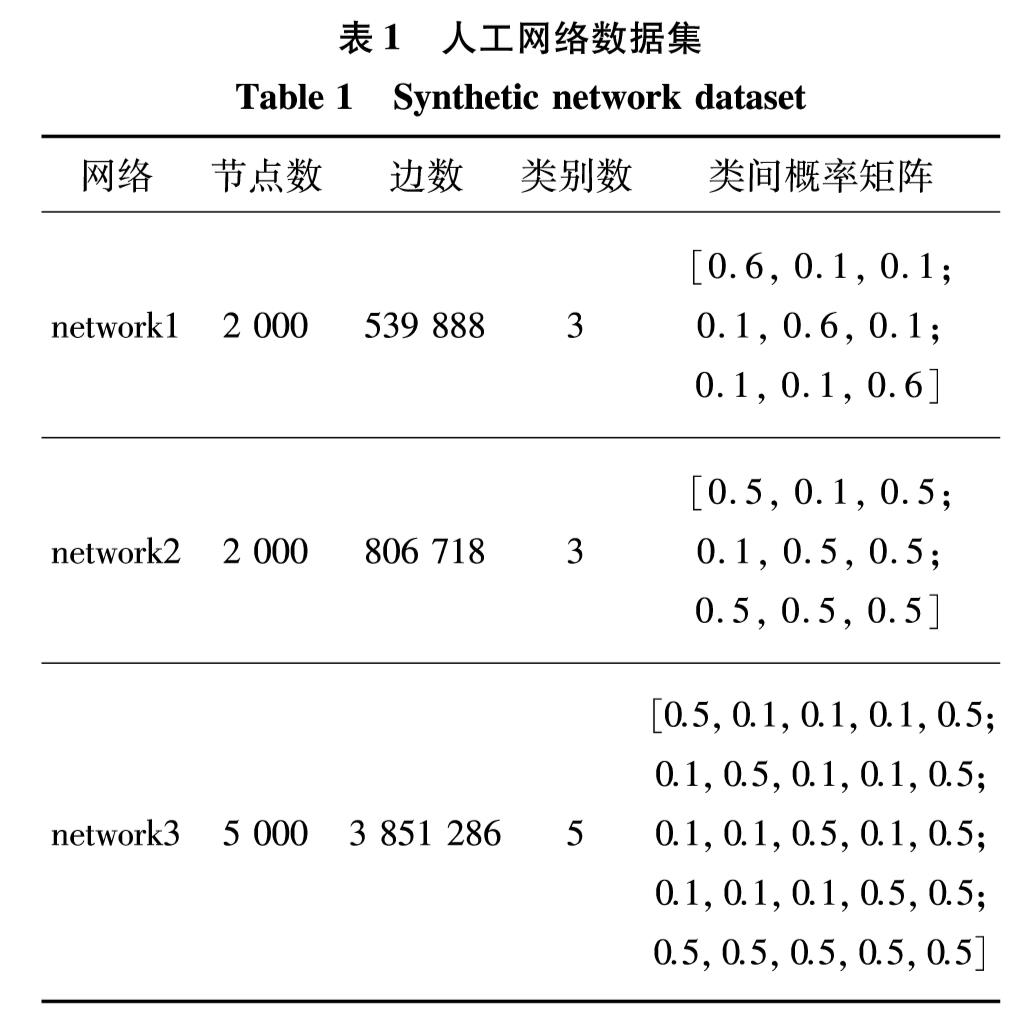
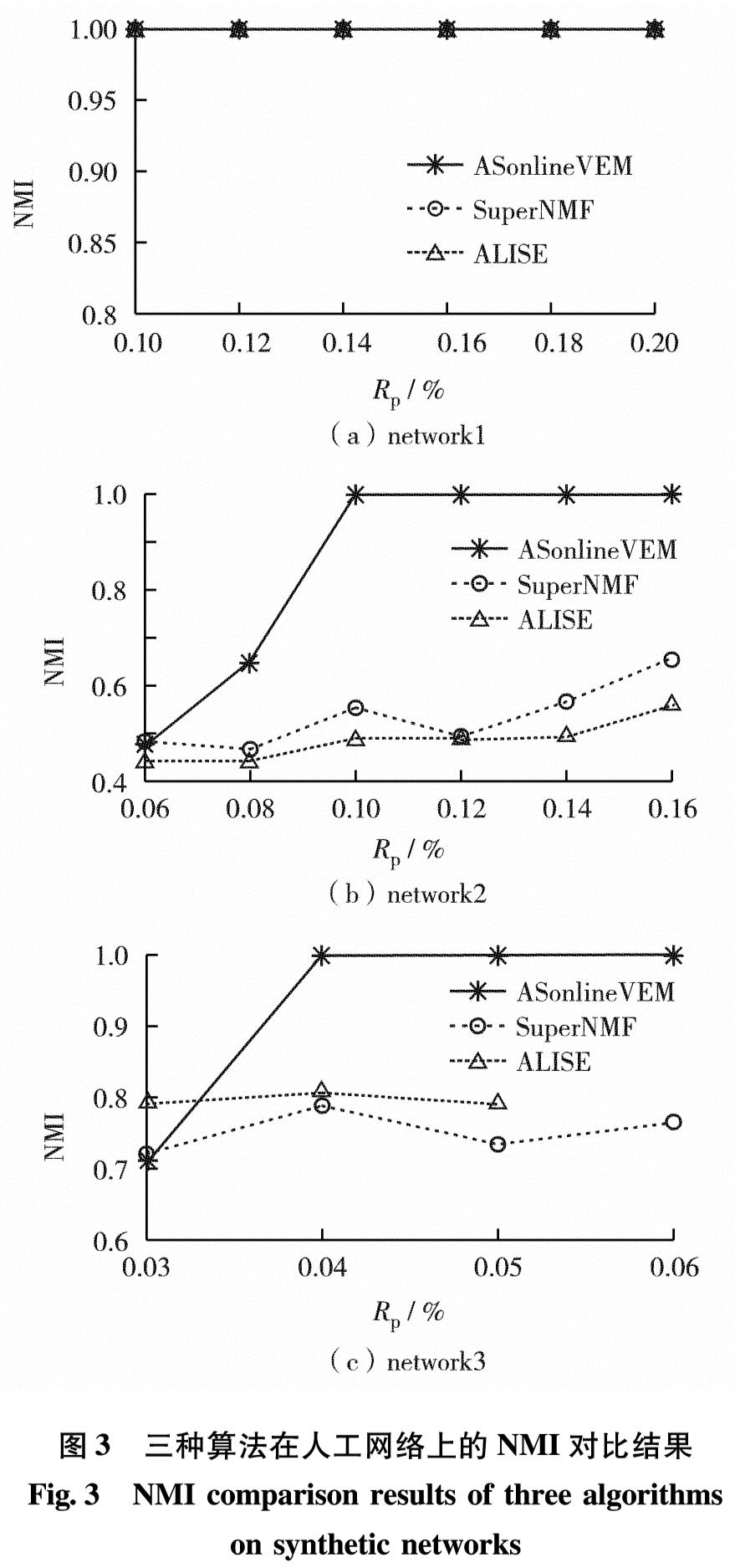
人工网络 采用ASonlineVEM、SuperNMF和ALISE算法对人工生成具有社区结构(network1)和二分结构(network2和network3)的网络进行实验,参数设置如表1.图3为3种算法在3个网络上的性能实验结果.由图3可见,在社区结构网络中,3种算法效果相当; 而在二分结构网络中,相同先验比例下ASonlineVEM算法准确率高于对比算法.如在network2中,RP=0.12%时,ASonlineVEM算法的准确率约是对比算法的2倍.在人工网络上,ASonlineVEM的准确率高于对比算法.
表1 人工网络数据集
Table 1 Synthetic network dataset
图3 三种算法在人工网络上的NMI对比结果
Fig.3 NMI comparison results of three algorithms on synthetic networks
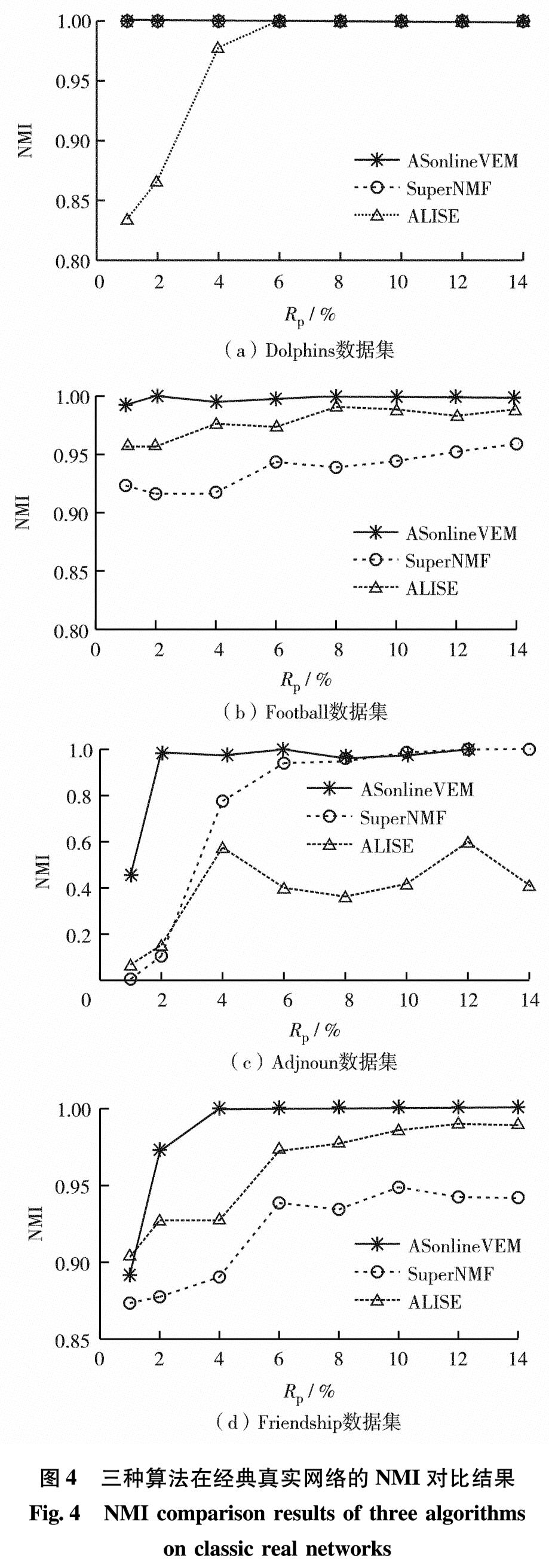
真实网络 本研究使用的真实网络数据集包括经典网络Dolphins、Football、Adjnoun和Friendship[18],以及Facebook网络Baylor、USC、Maryland和NYU[19].真实网络数据集合的具体参数请扫描论文末页右下角二维码见表S1.图4为分别采用ASonlineVEM、SuperNMF和ALISE算法在小规模经典网络数据集上测得的NMI结果.由图4可见,不同先验比例下ASonlineVEM算法性能均优于其他算法.
图4 三种算法在经典真实网络的NMI对比结果
Fig.4 NMI comparison results of three algorithms on classic real networks
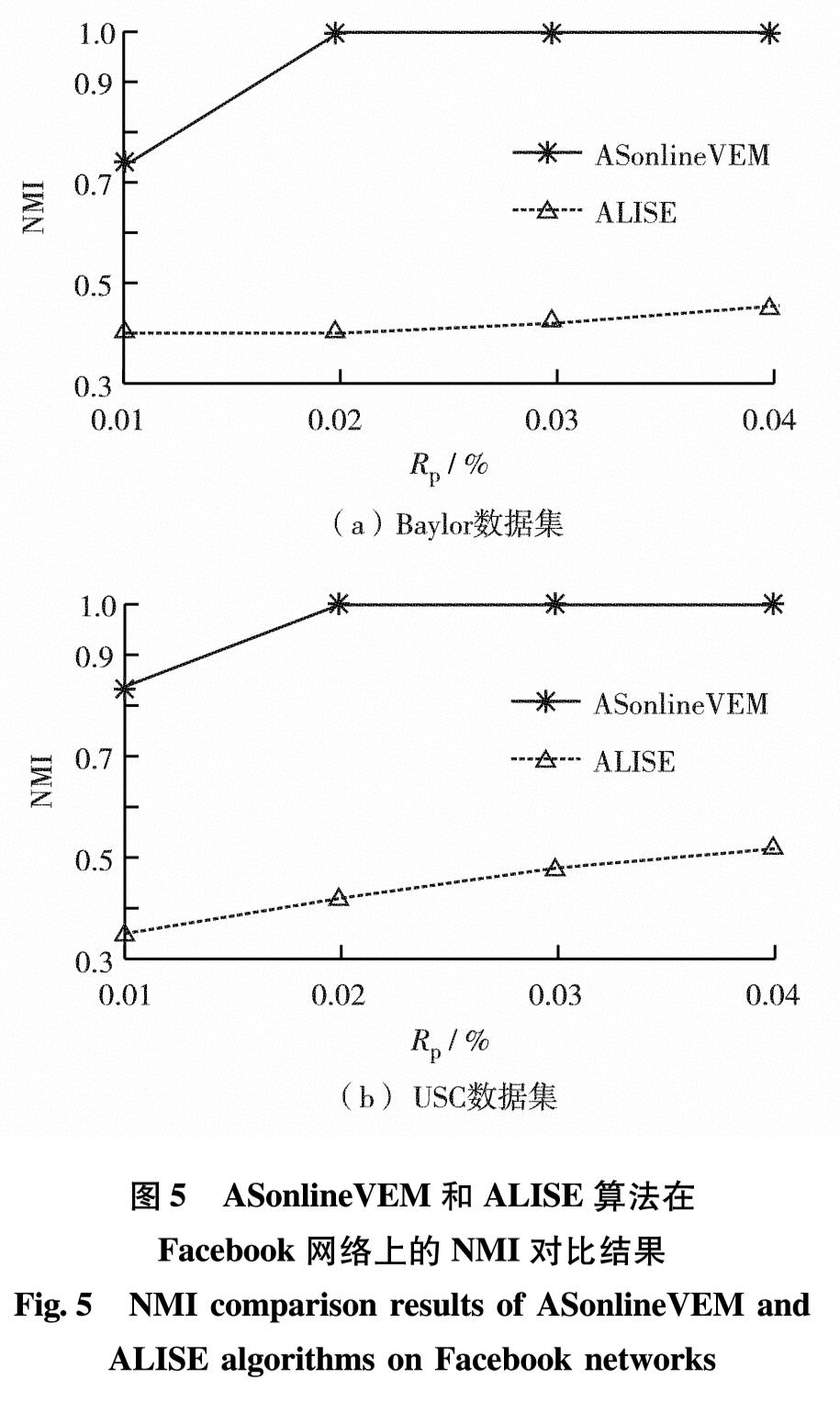
ASonlineVEM和ALISE算法都是基于迭代框架的主动半监督社区发现算法,图5为2种算法在真实大规模复杂网络Baylor和USC数据集上的NMI性能对比.由图5可见,在大规模复杂结构网络上,ASonlineVEM算法的准确性都优于ALISE算法.
图5 ASonlineVEM和ALISE算法在Facebook网络上的NMI对比结果
Fig.5 NMI comparison results of ASonlineVEM and ALISE algorithms on Facebook networks
对于具有社区结构的网络,ASonlineVEM算法初始通过主动策略选择代表节点进行标定,保证初始参数有较高的准确性,再利用代表节点的精确标定最大程度影响剩余节点.迭代过程主动选择不确定性且信息量大的节点进行标记,提高了算法发现网络结构的准确率.SuperNMF算法随机选择先验导致无法充分利用高质量先验信息.ALISE算法可发现社区网络的聚类结构,但非社区网络network2和network3的聚类结构属于二分结构,SuperNMF和ALISE算法主要处理的是社区结构发现问题,无法发现多类型网络聚类结构.
分析不同网络的准确率结果发现,随着先验比例的增加,ASonlineVEM算法较其他同类算法准确率更高、收敛速度更快、稳定性更佳,表明该算法效果均优于其他算法.
ASonlineVEM算法不仅能准确识别网络的聚类模式,还能高效处理不同规模网络.对于规模较小的基准网络,如Zout=9的GN网络,当Rp=2%时,ASonlineVEM、SuperNMF和ALISE算法运行时间t分别为0.258 7 、0.611 6和0.552 0 s.在网络节点较少的真实网络Football上,当Rp=14%时,ASonlineVEM、SuperNMF和ALISE算法的运行时间分别为0.185 4、0.364 0和4.296 4 s.可见,ASonlineVEM算法运行效率最高,其他小规模网络上也有相同运行结果.
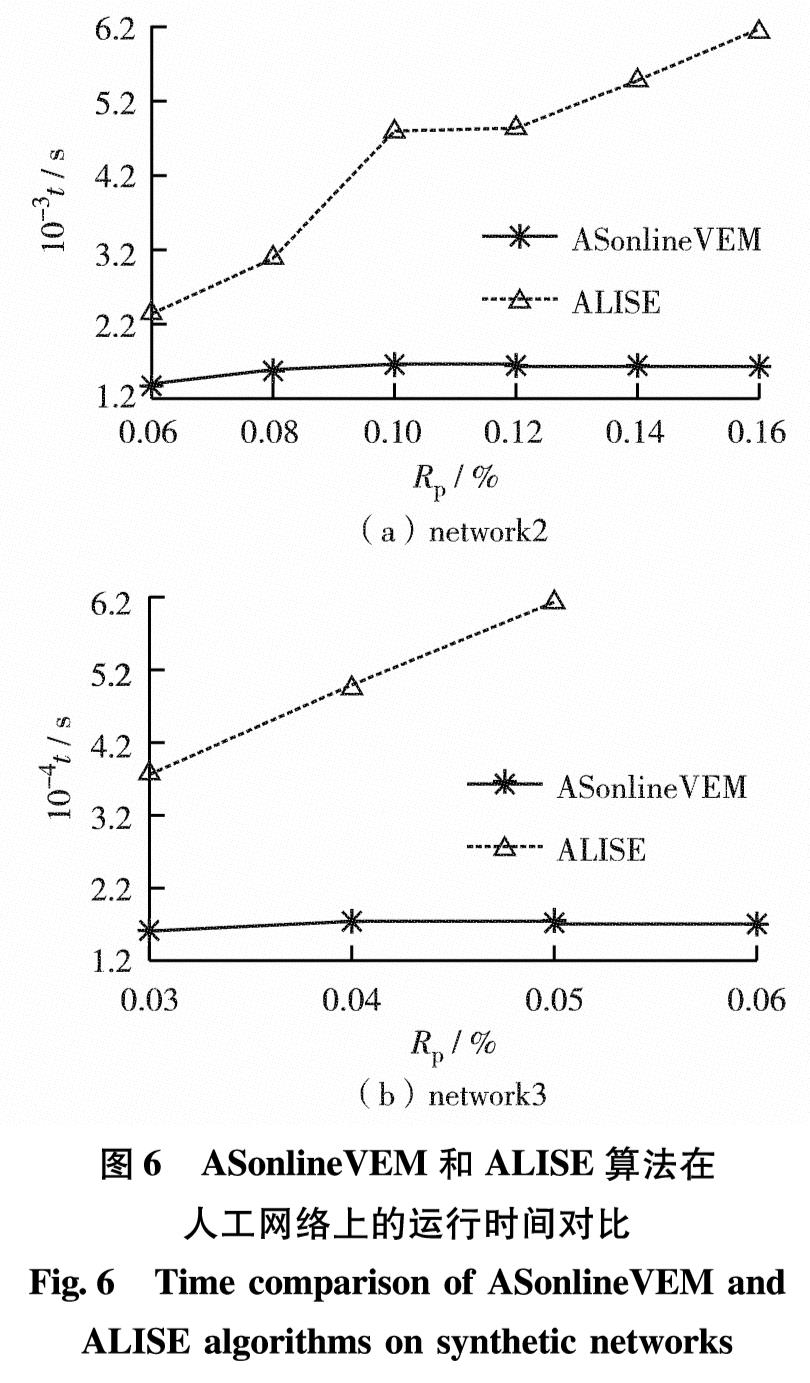
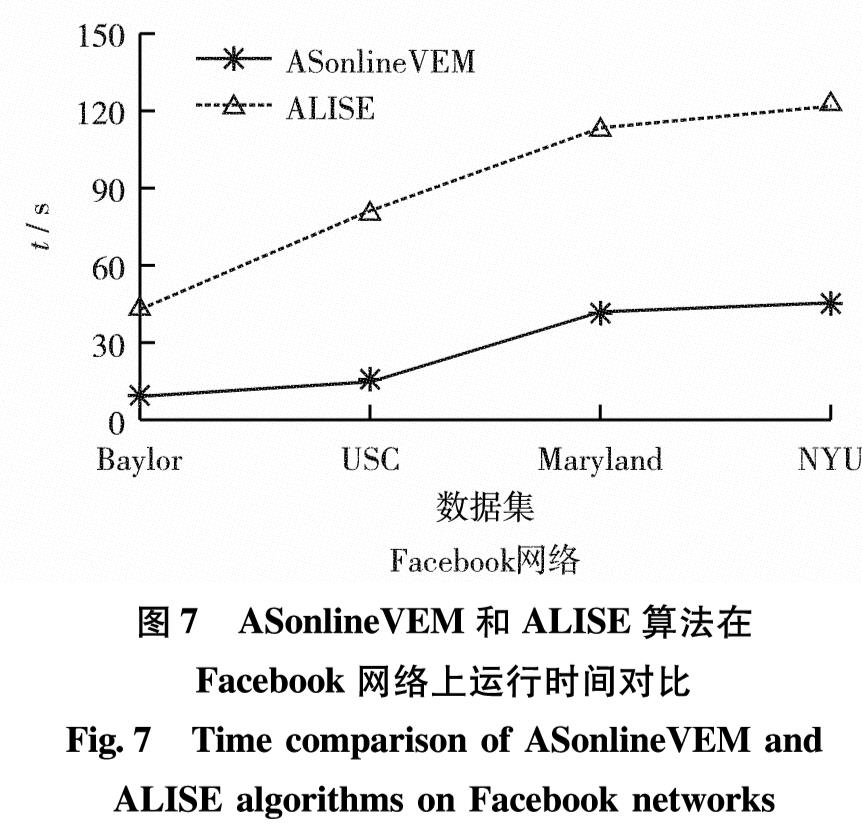
针对节点较多或边数较多的大规模复杂网络,为简单起见,给出部分大规模网络上ASonlineVEM和ALISE算法的运行时间对比结果.network2和network3人工网络的时间对比结果如图6.图7为两种算法在Facebook数据集上数据传输一次所需要的时间对比结果.总的来说,在不同规模网络上,ASonlineVEM算法明显比ALISE算法高效.
ASonlineVEM算法在迭代过程中,对已标记类别信息的节点将不在后续算法中估计其类隶属度,只计算剩余节点的类隶属度,大幅节省了算法耗时. ALISE算法每次迭代选择网络中最不确定的链接进行人工标记,而大规模网络的边数往往远大于节点数,这使ALISE算法每次迭代计算边不确定性的复杂度较大,导致算法运行时间长.
图6 ASonlineVEM和ALISE算法在人工网络上的运行时间对比
Fig.6 Time comparison of ASonlineVEM and ALISE algorithms on synthetic networks
图7 ASonlineVEM和ALISE算法在Facebook网络上运行时间对比
Fig.7 Time comparison of ASonlineVEM and ALISE algorithms on Facebook networks