3.2 评价指标
利用平均准确率(average precision, AP)、排位损失(ranking loss, RL)、1-错误(one-error, OE)和海明损失(Hamming loss, HL)4个评价指标[18]对多标记实验实验结果进行验证和评价度量.
测试集为{(xi, Yi)}mi=1Rd{+1,-1}L. 其中, Yi为隶属于样本xi的相关标记集合,经算法预测得到的标记集合记为h(x); 符号表示维度相乘.根据预测函数 fl(x)定义排序函数为rankf(x,l)∈{1, 2,…,L}.
AP为评估预测标记排在前列且正确存在于相关样本标记的平均概率,如式(12).该值越大表示分类效果越好,最优值为1.
AP(f)=1/m∑mi=1(1/(|Yi|)∑l∈Yi((k|rankf(xi, k)≤rankf(xi, l), k∈Yi))/(rankf(xi, l))))(12)
其中, Yi为隶属于样本xi的相关标记集合.
RL用于评估无关标记在相关标记的样本前列的多少,如式(13).该值越小表示分类效果越好,最优值为0.
RL(f)=1/m∑mi=1(1/(|Yi||Y^-i|)|{(l, k)|rankf,(xi, l)≥rankf(xi, k),(l, k)∈YiY^-i}|)(13)
其中, Y^-i为集合Yi在标记空间中的补集.
HL用于衡量样本在单一标记上的非正确匹配情况,如式(14).该值越小,分类效果越好,最优值为0.
HL(h)=1/m∑mi=11/L|h(xi)≠Yi|(14)
其中, Yi为隶属于xi的相关标记集合; h(·)为分类器,即可得xi的预测标记向量.
OE用于衡量最高排序中样本的标记不存在于相关标记集合中的情况,如式(15).该值越小,表示分类效果越好,最优值为0.
OE(h)=1/m∑mi=1{[arg maxl∈L f(xi,l)]Yi}(15)
在4个评价指标中,除去AP值越大越优,其余的越小越优.
3.3 实验结果及分析
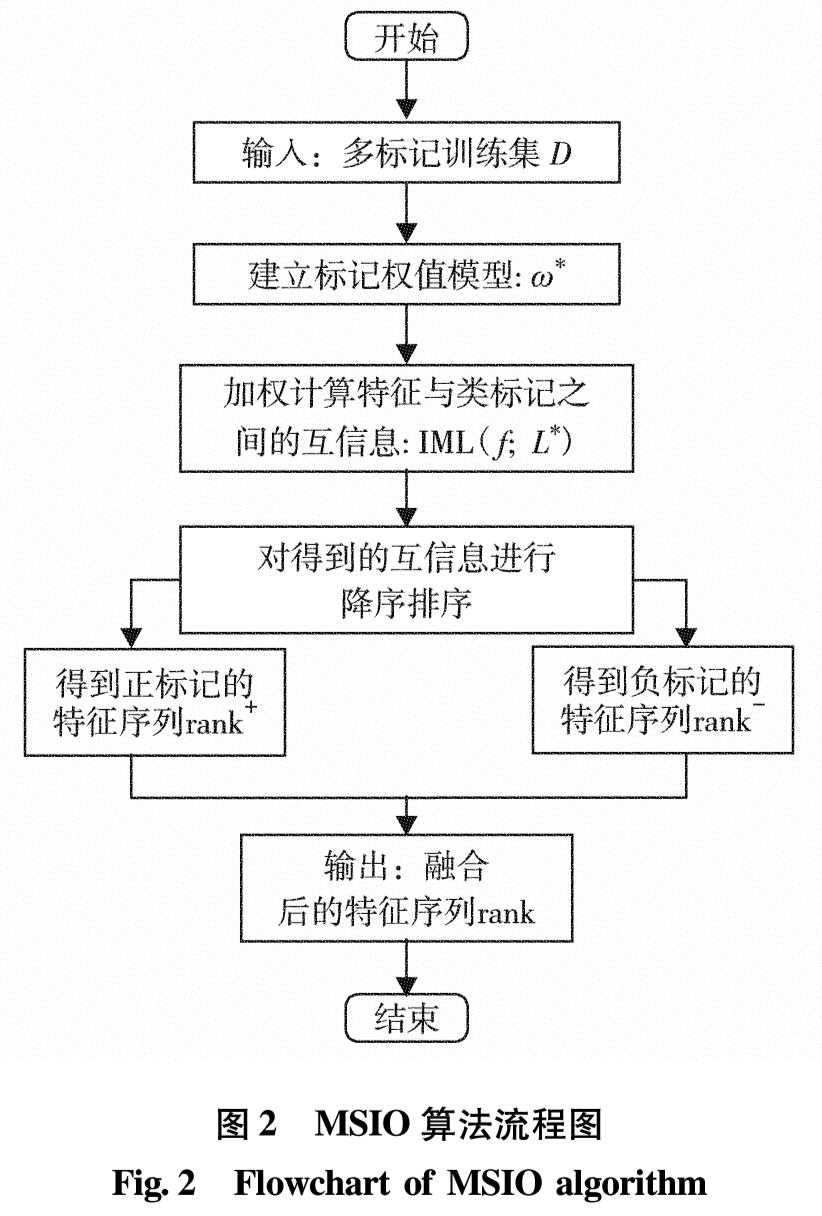
本研究实验代码均在Matlab2016a中运行,硬件环境Inter CoreTM i7-7700HQ CPU @ 2.80 GHz,8 Gbyte内存; 操作系统为Windows 10.以多标记k近邻(multi-label k-nearest neighbor, ML-kNN)[19]作为基础分类器,对基于最大相关性的多标记维数约简(multi-label dimensionality reduction via dependence maximization, MDDM)算法[20-21]、基于多变量互信息的多标记特征选择算法PMU(pairwise multivariate mutual information)[22]、 多标记朴素贝叶斯分类的特征选择(feature selection for multi-label naive Bayes classification, MLNB)算法[23]、 基于标记相关性的多标记特征选择(multi-label feature selection with label correlation, MUCO)算法[13]和MSIO算法的AP、RL、OE和HL值进行排序.其中,MDDM算法按照参数所选择的不同分为MDDMspc与MDDMproj算法.由于MDDM、PMU、MUCO和MSIO算法得到的是一组特征序列,于是设置特征子集的个数与MLNB算法一致,并设ML-kNN中的平滑系数s=1, 近邻个数k=10. 表2至表5列举了6种算法在数据集中的AP、RL、OE和HL值.
表2 六种算法在11个数据集中的平均准确率排序1)
Table 2 Average precision ranking of 6 algorithms in 11 datasets
表3 六种算法在11个数据集中的排位损失排序1)
Table 3 Ranking loss of 6 algorithms in 11 datasets
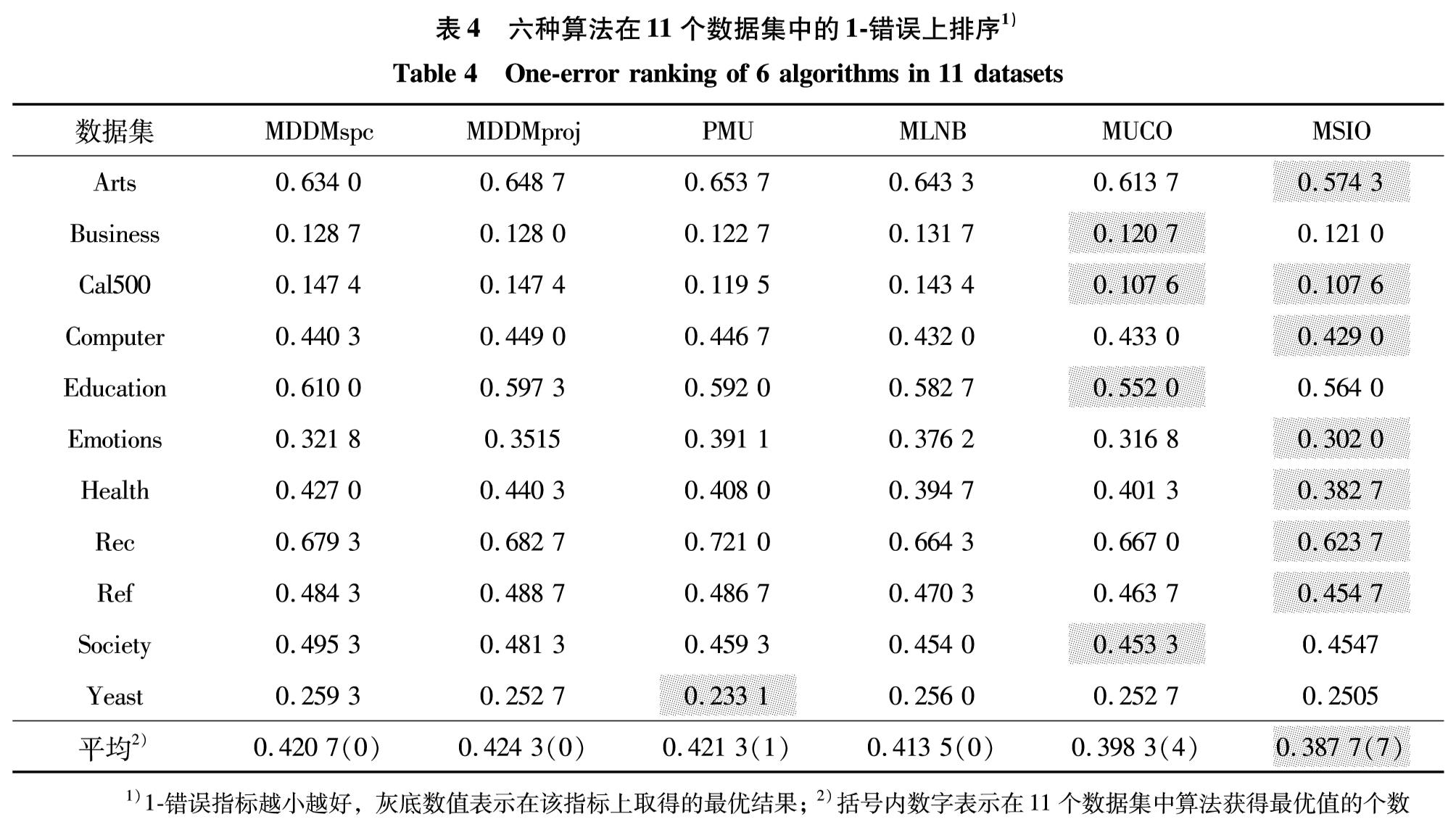
表4 六种算法在11个数据集中的1-错误上排序1)
Table 4 One-error ranking of 6 algorithms in 11 datasets
表5 六种算法在11个数据集中的海明损失排序1)
Table 5 Hamming loss ranking of 6 algorithms in 11 datasets
由表2至表5可见:
1)MSIO算法在4种评价指标中的最优数目和平均值均位列第1,且在Art、Computer、Rec和Ref数据集中的所有评价指标均优于其他算法.
2)在AP指标上,仅MUCO算法在部分数据集上占优,但最优的Cal500数据集也仅提高了2.15%; 在RL指标上,6种算法各有千秋,其中,在Emotions数据集中MDDMspc算法占优最大,为11.12%; 在OE和HL指标上,最优的分别高7.46%和3.58%.
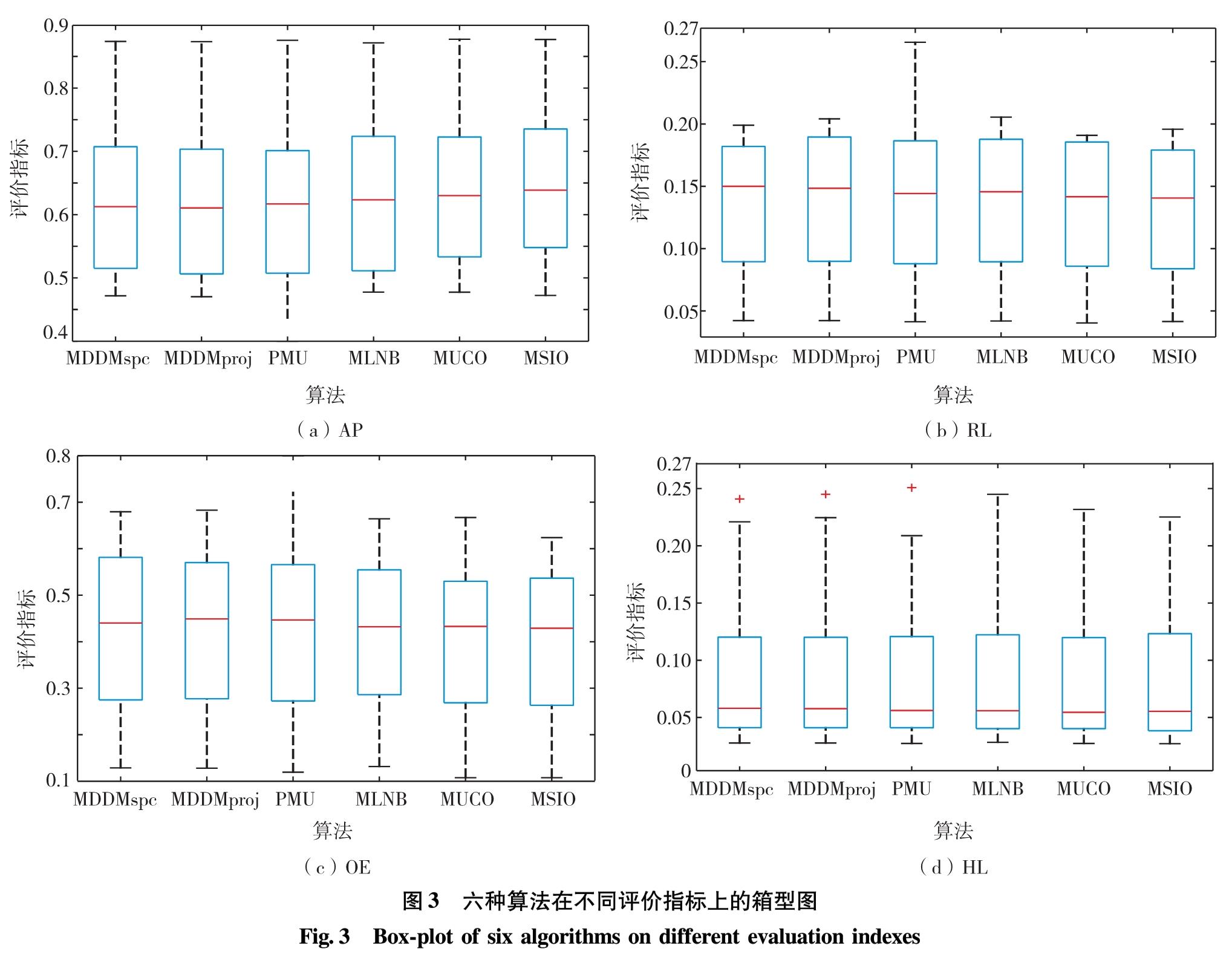
图3为6种算法在不同评价指标上的箱型图.由图3可见,6种算法在4种评价指标上展现的分类性能对比中,MSIO算法在箱形图中的中位数表现明显占优.可见,MSIO算法稳定性更好的,且分类精度更高,性能优于其他特征选择算法.
图3 六种算法在不同评价指标上的箱型图
Fig.3 Box-plot of six algorithms on different evaluation indexes
3.4 算法性能统计分析
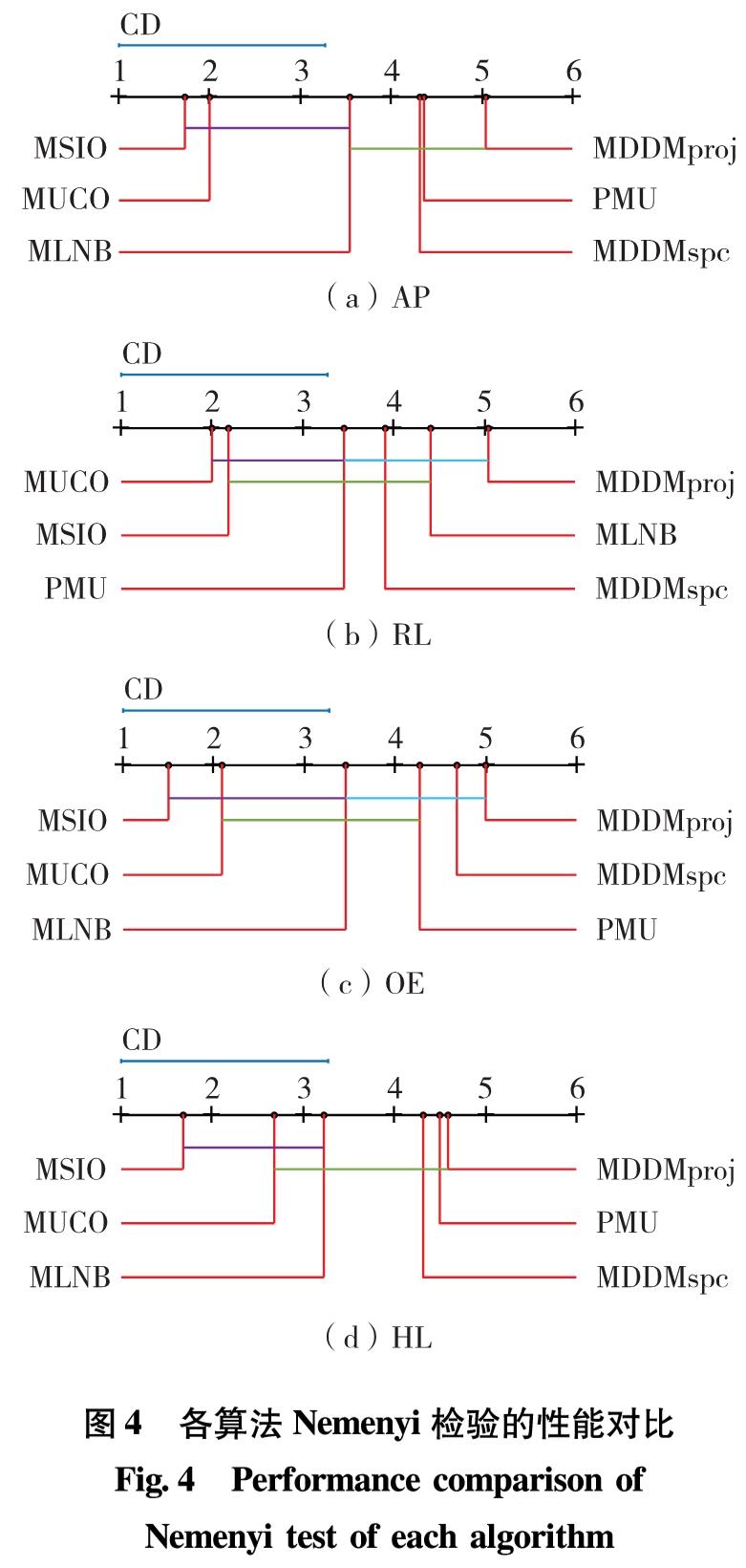
运用统计学知识,对在11个数据集上的实验结果进行显著性水平为5%的Nemenyi统计假设检验,若在所有数据集上两个对比算法平均排序的差低于临界差(critical difference, CD),则认为它们无显著性差异,否则,认为这两个对比算法有显著性差异.本研究设显著性水平α=0.05, qα=2.850(第k个对应数), 算法个数k=6, 数据集个数N=11,则
CD=qα(k(k+1)/6N))1/2=2.274(16)
图4给出了各个算法在不同评价指标下的对比.坐标轴上的刻度描述了各种算法在不同指标中的平均排序,轴上数字越小,表明算法性能越优.不同线型相接的算法表示在性能之间无显著性差异.由图4可见,MSIO算法排名除在RL指标上比MUCO稍微逊色,在其余指标中均明显较优.
图4 各算法Nemenyi检验的性能对比
Fig.4 Performance comparison of Nemenyi test of each algorithm

![表1 多标记数据集[17]<br/>Table 1 Multi-label datasets[17]](2020年3期/pic15.jpg)