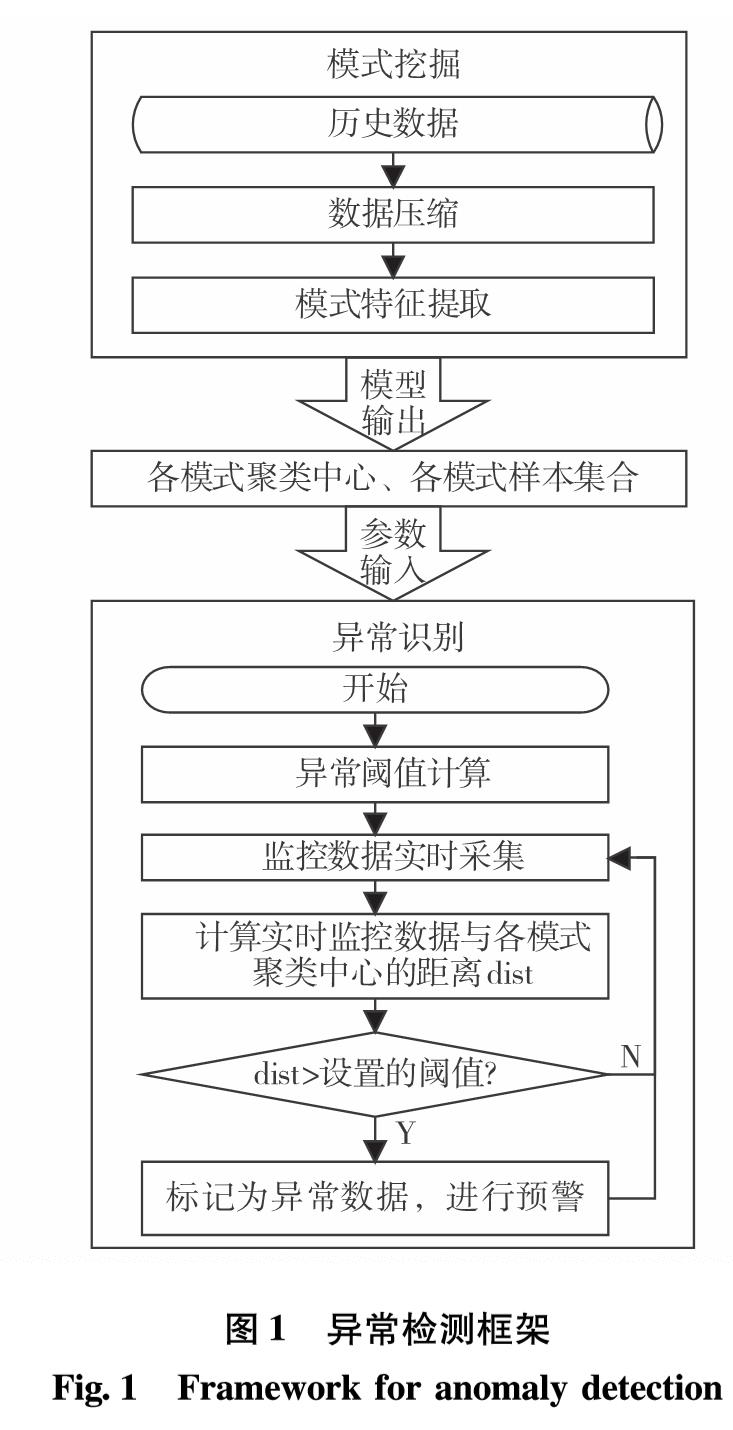
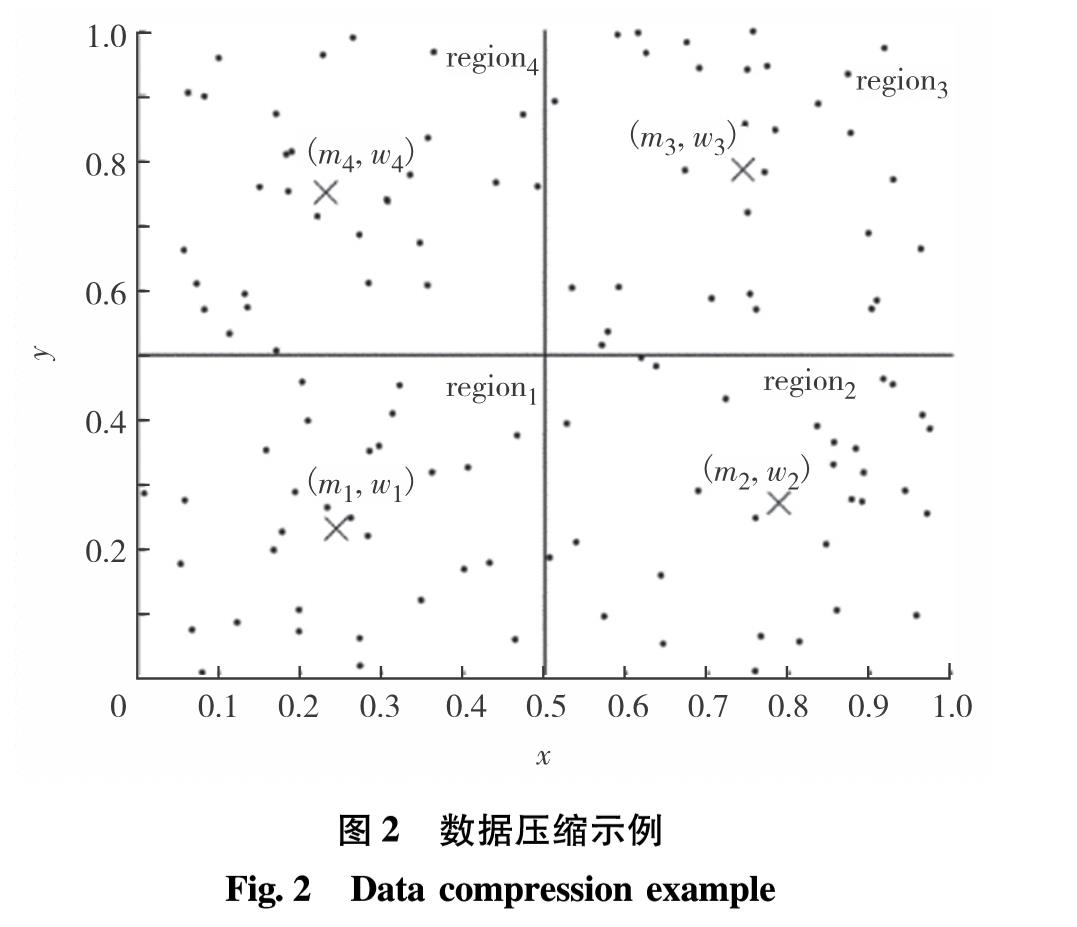
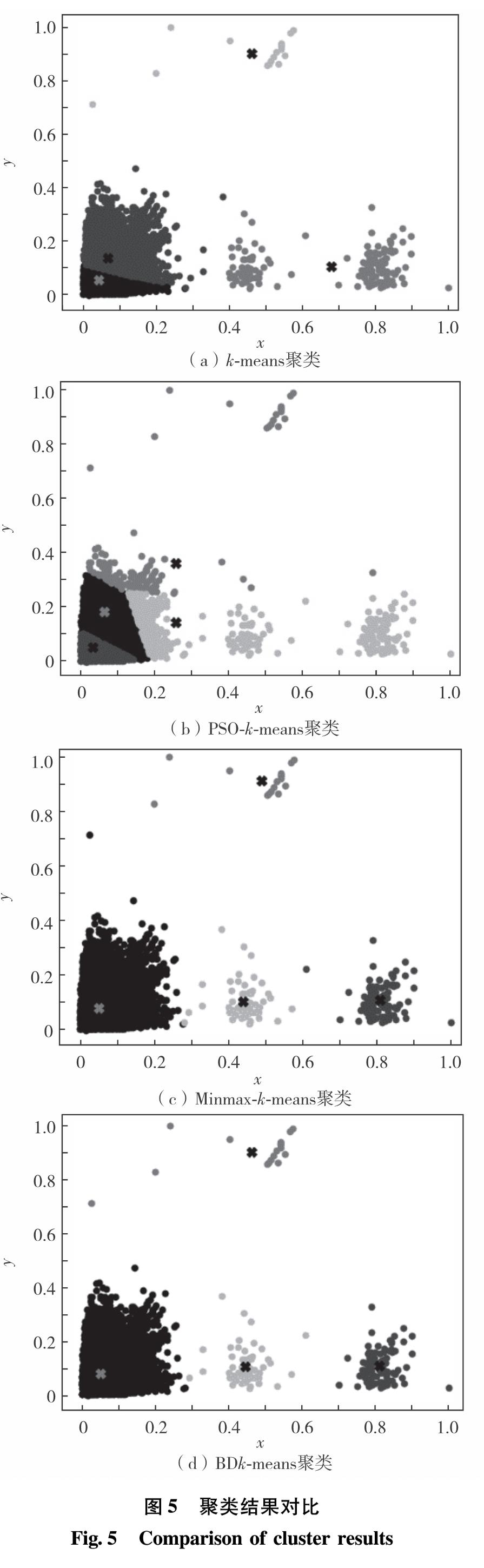
模式挖掘的目的是从众多的历史数据中,识别出系统的正常模式. 由于电力信息系统单位时间采集一次数据,采集频率高、时间跨度大,具有众多相似或重复数据,在特征提取过程中将进行大量重复计算. 所以,模式挖掘过程分为数据压缩和模式特征提取两个步骤.
1.1.2 基于BDk-means的模式特征提取
BDk-means算法在传统k-means算法的基础上,引入聚类边界再分配机制(当边界密度大于簇密度时,每次迭代使聚类边界向密度小的方向移动),使边界密度逐步向下收敛,得到边界清晰的聚类划分,准确提取正常模式,主要包含初始聚类中心选择、模式更新和聚类中心更新等3个步骤.
为便于描述本研究提出的BDk-means算法,给出以下定义.
定义1 簇边界区间:给定任意两个簇i、 j和边界范围参数s, 簇边界区间(edgei, j)表示处于直线L1和直线L2之间的平面空间,其中, L1(a1x+b1y+c1)和L2(a2x+b2y+c2=0)分别表示线段CiCj的垂直平分线L0前后平移s的直线,如图3.
图3 边界划分示意
Fig.3 Edge demarcation
定义2 边界样本:给定任意两个簇i和j, 其边界样本ePointi, j表示处于平面空间edgei, j内的样本点(x, y), 如图3中介于直线L1和直线L2之间的样本点P(x, y), 满足约束:
{a1x+b1y+c1>0
a2x+b2y+c2<0
P(x, y)∈Pi, P(x, y)∈Pj(2)
1)初始聚类中心选择
传统k-means算法初始聚类中心选择过程具有随机性,选择不同的初始聚类中心,算法陷入的局部最优解不同,可能得到不理想的局部最优解. 因此,本研究提出一种改进的初始聚类中心选择算法,首先对于给定数据集建立如图4所示的坐标空间,然后确定坐标空间中与原点距离的最大样本点maxP和最小样本点minP,并以原点为圆心将坐标空间切分为图4所示的k个等宽圆环空间,每个圆环空间Ci表示为
Ci={in_ri, out_ri}(3)
其中, in_ri和out_ri分别代表圆环空间的外环和内环, 具体定义为
{in_ri=dist(o, minP)+(i-1)×val
out_ri=dist(o,minP)+i×val(4)
val=(dist(o, maxP)-dist(o, minP))/k(5)
其中,dist(o, minP)和dist(o, maxP)分别表示原点o到样本点maxP和minP的距离.
图4 初始聚类
Fig.4 Initial clustering
本研究将各圆环内样本点的集合视为初始簇,并基于加权均值更新聚类中心:
cji=1/N∑|Pi|l=1(wl×Pi[l])(6)
N=∑|Pi|l=1wl(7)
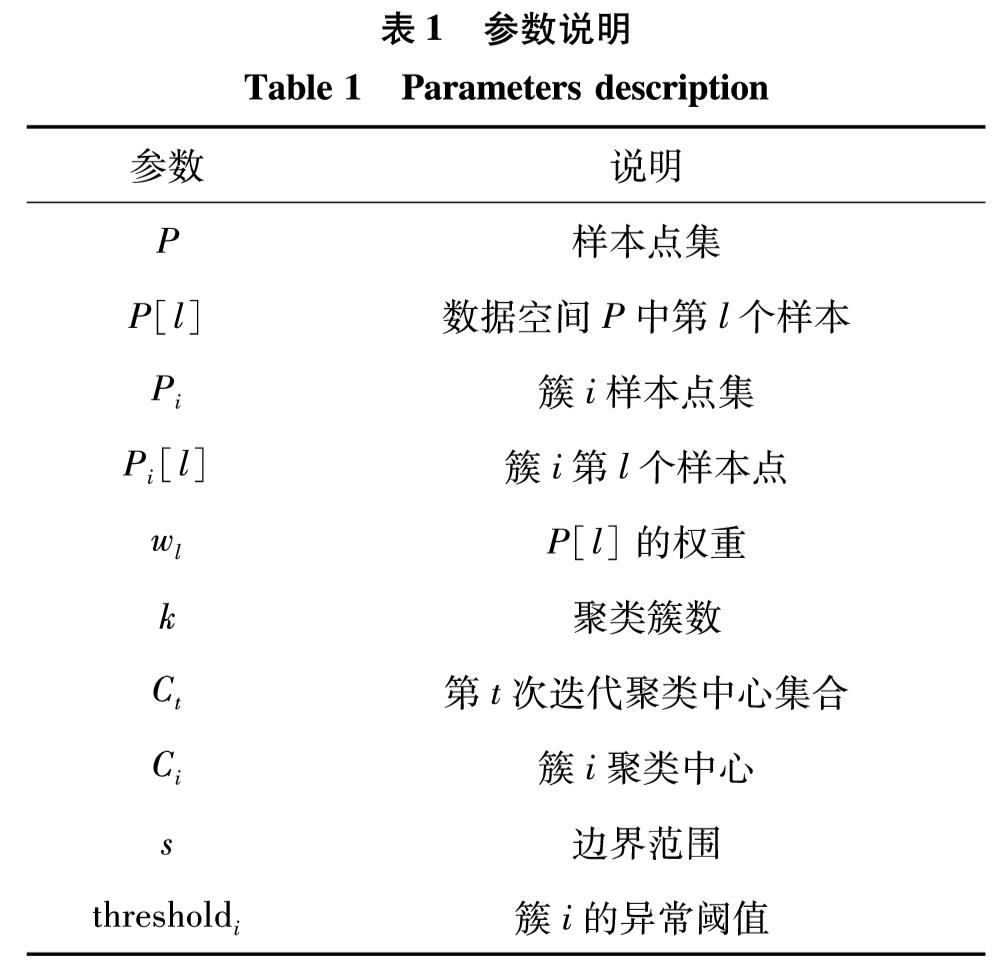
其中, |Pi|为Pi集合中样本点的个数; wl为经数据压缩后样本点Pi[l]的权重.
2)模式更新
一般来说,电力信息系统数据模式分布具有差异性(图3),模式C1中样本离中心距离较小,模式C2中样本离中心距离较大.
传统k-means算法以最近邻准则标记样本点类别,以图3中C1C2的垂直平分线L0划分两种模式,将L0至L2中的样本点划分为模式C1, 然而L0两侧样本点分布类似,均为模式C2中的样本点. 因此,本研究提出一种边界再分配策略,首先以最近邻准则划分初始簇,分配样本点为其最近邻簇Pm,获得初步聚类划分P1, P2, P3, …, Pk,样本点所属类别由式(8)确定:
m=argmini dist(C, Pi[l])(8)
计算每一样本点与最近邻簇心Ci和次近邻簇心Cj垂直平分线的距离,当其小于给定的边界范围s, 则视该样本点为边界edgei, j的边界样本点ePointi, j. 通过比较边界样本点密度bDensi, j与簇i、 j相对聚类边界edgei, j的密度cDensi, j和cDensj, i, 当边界密度bDensi, j>cDensi, j或cDensj, i时,划分边界样本点到簇相对密度更大的簇,否则以最近邻准则标记样本点类别.
边界密度bDensi, j为
bDensi, j=(|ePointi, j|)/s(9)
其中, |ePointi, j|为边界edgei, j样本点数量; s为给定的边界范围参数. 簇i相对聚类边界edgei, j的簇相对密度为
cDensi, j=(|Pi|)/(ri, j)(10)
ri, j=dist(ci, cj)/2(11)
其中, |Pi|表示簇i的样本点数量.
3)聚类中心更新
与传统k-means算法类似,BDk-means算法以每类样本点的均值作为聚类中心. 不同点为当每一样本点Pi[l]与其他聚类中心Cj-cji的最小距离dMini[l]大于该样本点与原聚类中心的距离时,BDk-means算法才更新该样本点所属簇的聚类中心,以减少陷入局部最优解的概率. 即满足
dist(Pi[l], cj-1i)<dMini[l], Pi[l](12)
dMini[l]=min(dist(Pi[l], Cj-cji))(13)
其中, dist(Pi[l], Cj-cji)表示样本点Pi[l]到Cj-cji距离的集合,才更新聚类中心.