基金项目:天津市科技特派员资助项目(18JCTPJC54300)
作者简介:马 杰(1978—),河北工业大学教授、博士生导师.研究方向:人工智能.E-mail:jma@hebut.edu.cn
中文责编:英 子; 英文责编:木 柯
作者简介:马 杰(1978—),河北工业大学教授、博士生导师.研究方向:人工智能.E-mail:jma@hebut.edu.cn
中文责编:英 子; 英文责编:木 柯
DOI: 10.3724/SP.J.1249.2020.01079
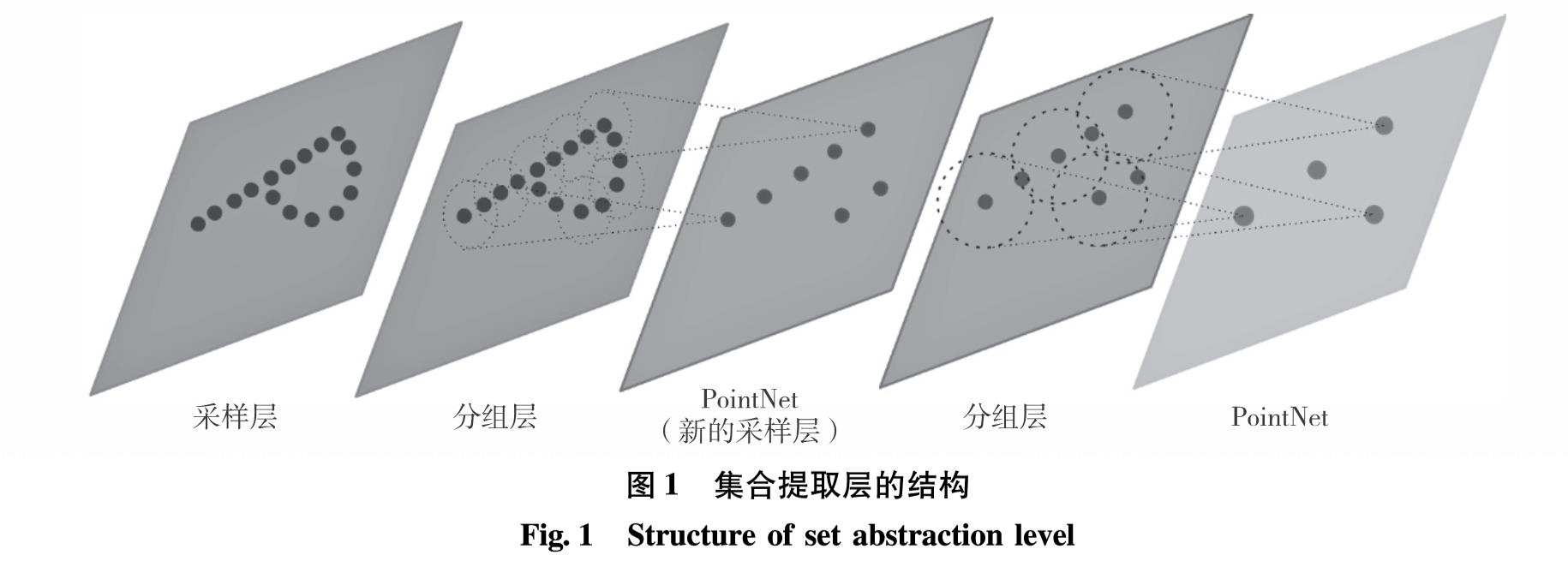
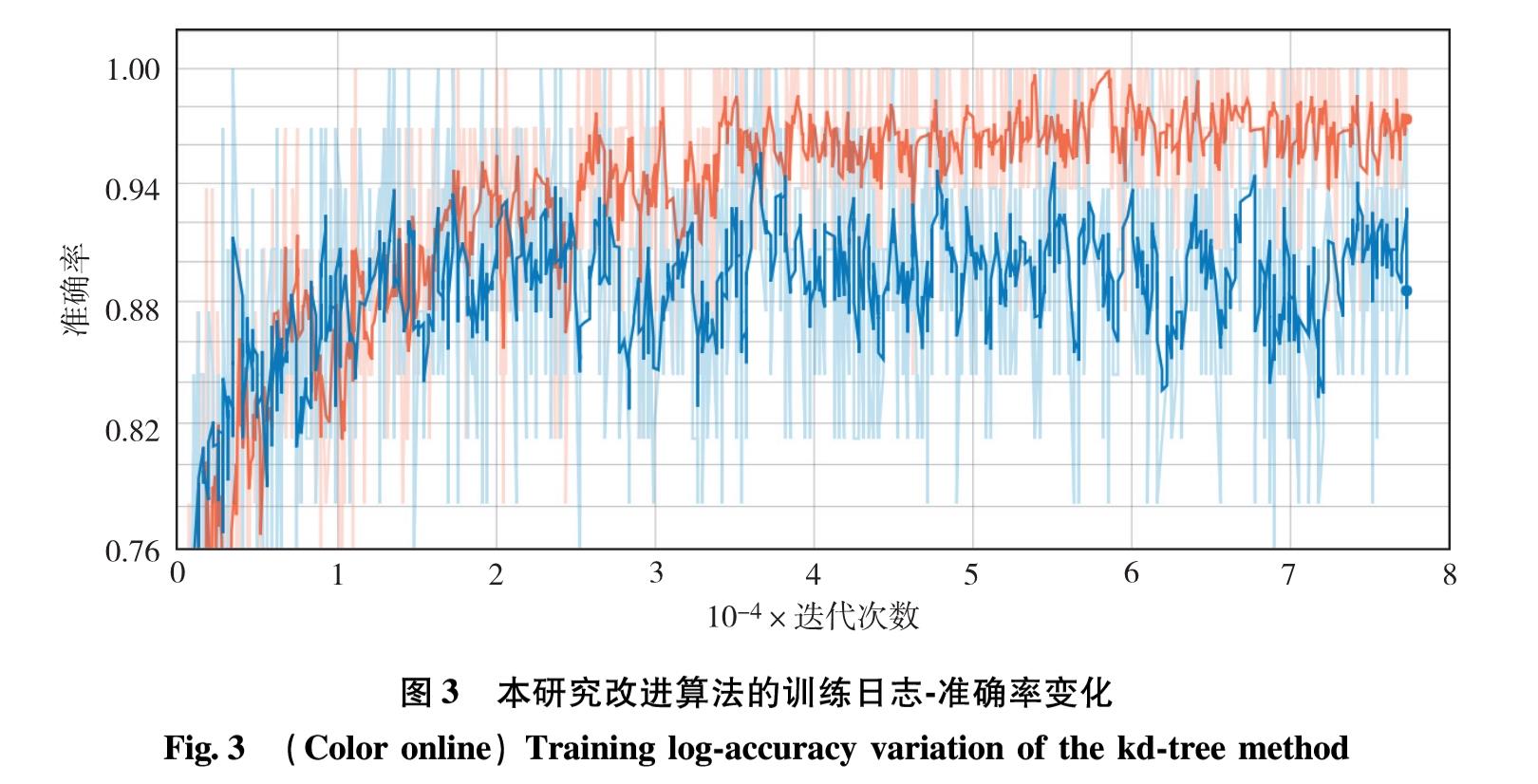
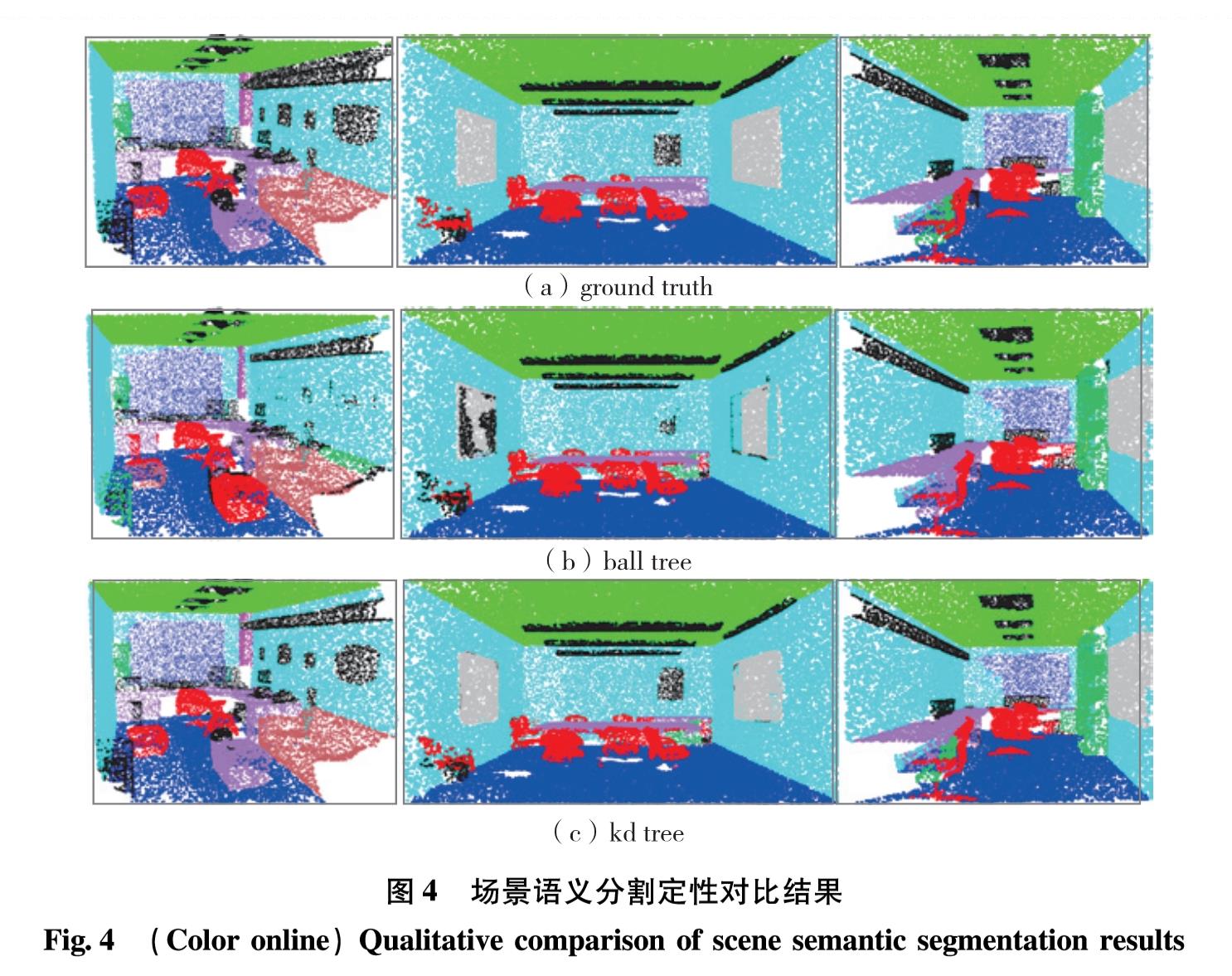
为解决PointNet++精度较低、耗时较长,且对输入点的噪声敏感的缺陷,引入一种高效的k维树(k-dimensional tree, kd tree)邻域查询方法,通过构建kd tree查找查询点周围指定半径内的近邻点,构造局部区域集,完成在PointNet++分组层上的局部特征提取.针对原网络训练过程中存在的过拟合问题,引入随机失活(dropout)正则化,减少网络收敛训练的时间.在Ubuntu14.04系统下搭建TensorFlow的图形处理器深度学习环境,并在ModelNet40数据集上进行训练和测试.实验结果表明,分别为当查询半径为0.1、0.2和0.3时,该查询方法的分类准确率分别为91.1%、92.1%和94.3%,皆优于PointNet++方法,且网络训练用时更短.改进后的结构在斯坦福三维语义分析数据集(Stanford 3D semantic parsing dataset)上进行语义分割实验平均交并比(mean intersection over union, MIoU)达57.2%,且其对于遮挡物体的鲁棒性更高.
PointNet++ is one of the effective deep learning methods to deal with the point cloud classification. However, there are some problems in this method including low precision, being time-consuming and sensitive to the noise of input points. In order to deal with these problems, we propose an efficient neighbor query method in which a k-dimensional tree(kd tree)structure is constructed to find the neighbor points within a specified radius around the query points, and the local features are extracted at the grouping layer of PointNet++. Aiming at the overfitting problem existing in the original network training process, we introduce the dropout regularization and thus reduce the training time of network convergence. The experiment environment is TensorFlow framework under Ubuntu14.04 system. The training and testing experiments are conducted based on ModelNet40 dataset. The classification accuracy of this method reaches 91.1%, 92.1% and 94.3% when the query radius is 0.1, 0.2 and 0.3, which is higher than PointNet++, and the kd tree method takes less time than the original method. At the same time, the improved structure has better semantic segmentation performance on the Stanford 3D semantic analysis dataset(mean intersection over union reaches 57.2%), which demonstrates the proposed method being more robust to occlusion objects.