3.1.2 预测方法及流程
现有农机总动力预测方法主要有两类:① 建立农机总动力的时间序列预测模型,采用灰色预测、BP 神经网络[19]、模糊神经网络、支持向量机(support vector machine, SVM)和组合预测模型等方法; ② 建立回归模型,选取影响农机总动力增长的因素,使用回归模型建立农机总动力与影响因素的关系模型,进而对农机总动力进行预测.本研究使用基于相空间重构和BP神经网络相结合的预测方法.
时间序列的相空间重构理论就是通过一维时间序列{x(i)}的不同延迟时间τ来构建d维的相空间矢量 y(i)=(x(i), …, x(i+(d-1)τ)). 其中, 1≤i≤n-(d-1)τ.
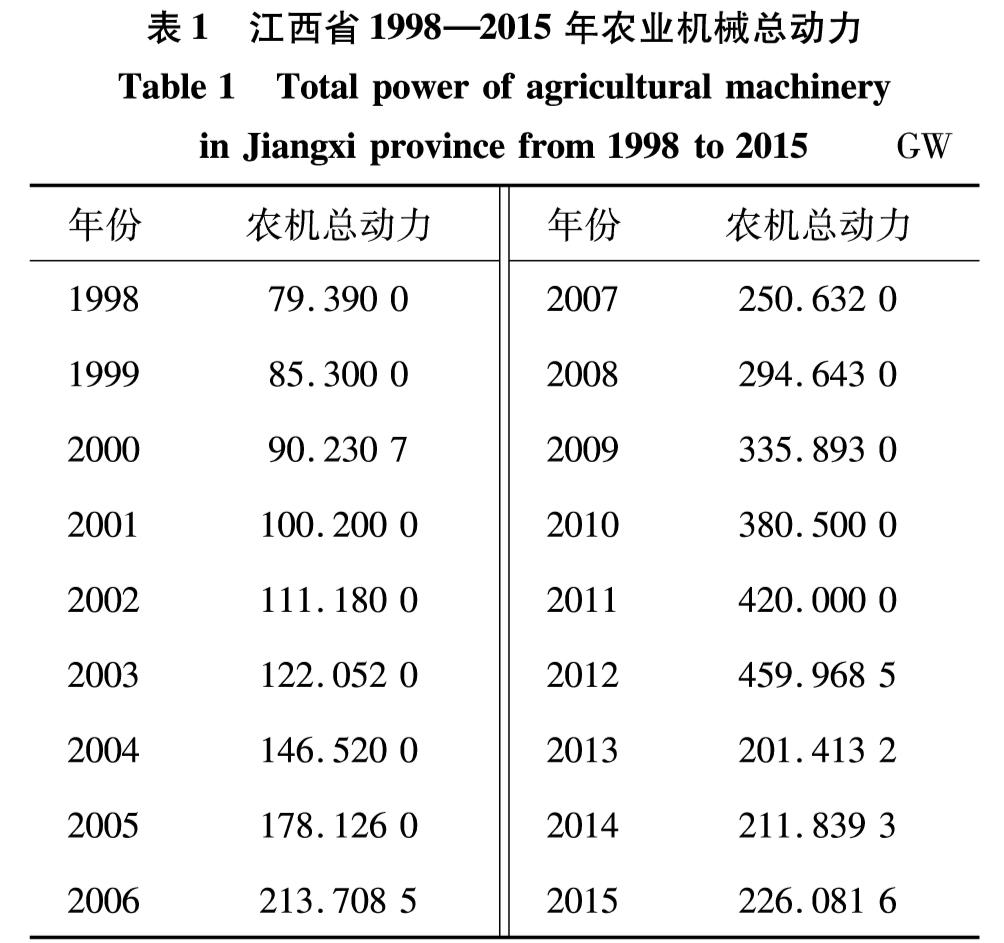
江西省农机总动力数据是每个年份对应的数据,本研究取τ=1 年, d=3, 即选取顺序序列连续3年的农机总动力数据来预测第4年的数据.图3是农机总动力预测方法步骤描述图.
1)对江西省农机总动力数据进行归一化预处理:
xi'=a+(b-a)(xi-xmin)/(xmax-xmin), i=1, 2, …, n. 其中,xi是输入样本数据; xi'是归一化后的数据; n是样本数.
2)根据相空间重构理论确定输入样本维数d=3;
3)根据2)中的m选择神经网络输入层结点个数,构造出BP神经网络预测模型;
4)划分训练集和测试集.从原始数据中选择部分训练数据作为训练集输入到网络完成训练,直到训练达到要求为止,记录训练完成时的网络参数,若不符合训练目标,则返回3);
选择测试样本输入,得到第一个预测点值,然后将第1点的预测值加入原数据集,预测第2点; 依此类推,逐步生成预测结果.
图3 农机总动力预测方法步骤描述图
Fig.3 Stepwise description chart of forecasting method for agricultural machinery total power
实验选取顺序序列连续3年的农机总动力数据来预测第4年的农机总动力数据,所以采用3-20- 40-1型网络模型结构,训练5×104次,训练的目标精度定为1×10-5,学习速率α=0.01,网络传递函数采用tansig函数,训练函数采用traingdx函数.把3层BP神经网络以同样的条件训练的结果作为基线(baselines).
3.1.3 预测结果及评价
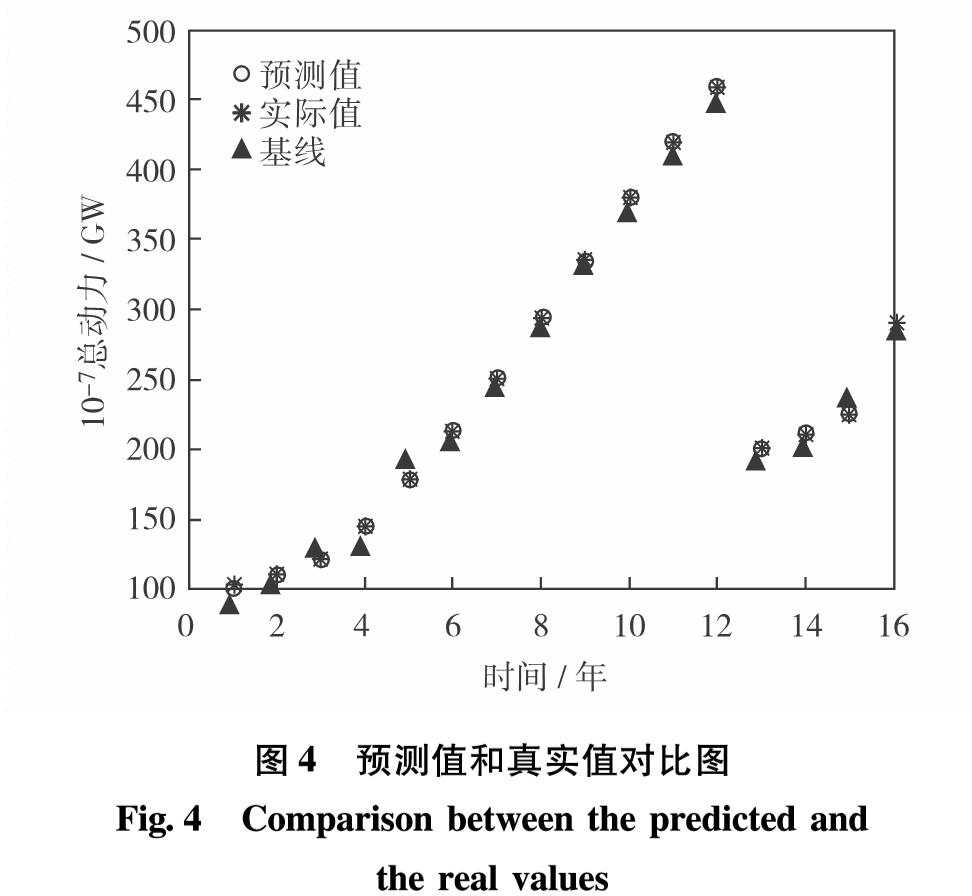
网络预测的预测值、真实值和基线值的分布比较结果如图4.
图4 预测值和真实值对比图
Fig.4 Comparison between the predicted and the real values
使用4层BP神经网络进行预测得出2016—2020年江西省农机总动力依次为289.73、318.65、387.54、412.89和458.56 GW.
采用均方误差(mean square error, MSE)作为评价指标,其值为
MSE=1/n∑mi=1wi(yi-(^overy)i)2(5)
其中, yi为每年总动力真值;(^overy)i为每年总动力估计值.迭代求解设定的MSE值的示意图请扫描论文末页右下角二维码查看图S6.由式(15)计算可知,MSE误差最终达到目标值1×10-5.
3.2 股票预测
股票是投资者的主要投资手段之一,但它是一个高度非线性的动态系统,其变化受到多方面的影响.研究股票序列价格预测不仅对投资者有很大的市场利益,也有很大的实际应用意义.MATTHEW等[20]提出人工神经网络在预测股票价格方面比其他模型更适合,至此,反馈神经网络、径向基神经网络等经典的基于神经网络的方法被应用到股票预测领域.
3.2.1 实验数据
影响股票价格趋势预测的因素很多,并且大多具有高非线性.本研究从同花顺软件中提取1990-12-20—2018- 03-30时间段内,上证指数(股票代码:000001)每日的开盘价、最高价、最低价、收盘价和成交量信息作为股票价格的数据特征,来分析这些信息对股票价格的反应趋势.共提取到 6 671条的每日股价信息,表头信息包括日期、开盘价、收盘价、最高价、最低价、成交量等信息.因此,针对DBN和T-DBN模型,输入特征包括开盘价、收盘价、最高价、最低价和成交量,输出特征为某支股票的预测最高价.
3.2.2 预 测
将上证指数股票数据训练样本分别输入DBN和T-DBN模型并进行训练,再将测试样本输入最终模型进行预测,通过比较两者预测的效果和准确率,借此评价这3个模型.实验中训练集和测试集的占比分别为85%和15%,上证指数股票数据共有6 671条数据,即将前5 670条数据作为训练集数据,将第5 800~6 671条数据作为测试集.
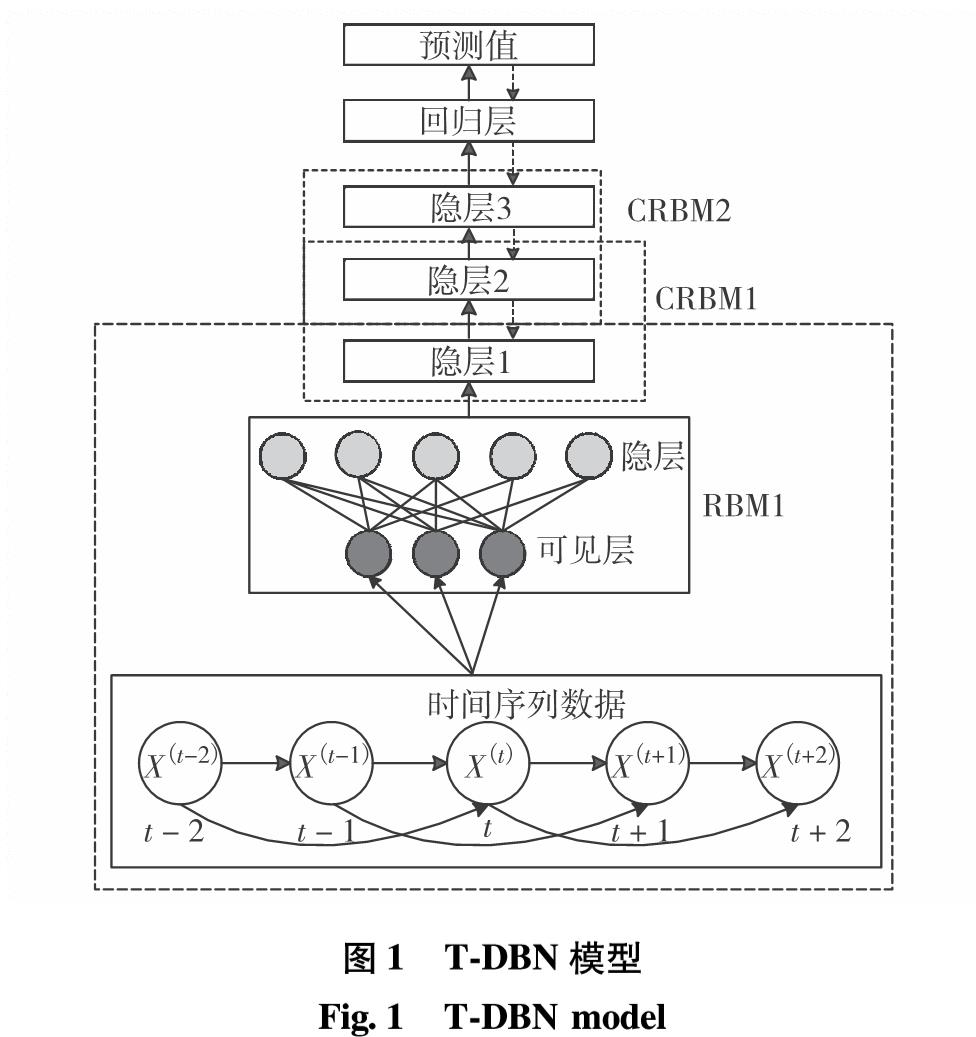
LSTM模型共迭代2 000次,设10个隐层单元,5个输入层和1个输出层神经元, α= 6×10-4.DBN模型采用4层5-20-20-1结构,用输入层和隐层构成第1个RBM,用隐层1和隐层2构成第2个RBM,另外一层进行逻辑回归的输出层,输入节点5个,两个隐层各20个节点, α=0.01, 最大预训练和反向微调次数为100.T-DBN模型采用5-20-20-15-1结构,用输入层和隐层构成RBM,用隐层1和隐层2构成第1个CRBM,用隐层2和隐层3构成第2个CRBM,另外一层进行分类回归softmax的输出层,设重构误差最大值为95%,隐含层3个,输入节点5个,第1个隐层节点数为20,第2个隐层节点数为20,第3个隐层节点数为15,输出层节点数为1, α=0.01, 最大预训练和反向微调次数皆为50.
将测试集数据分别输入到以上训练好的LSTM、DBN和T-DBN模型中,得到的股票数据真实值和预测结果(请扫描论文末页右下角二维码见图S7),两者基本吻合.
3.2.3 结果评价
使用预测正确率指标acc对模型进行评价,如式(6).预测正确率越大,表明模型的预测性能越好,对预测股票价格趋势越准确.
acc=n/len(test_predict)(6)
其中, n为股票最高价的预测值与真实值的绝对值误差≤50的正确记录的个数; len(test_predict)为预测出的记录数量.
采用股票真实值和实验所得的预测值,分别计得LSTM、DBN和T-DBN模型的预测准确率为74.6%、77.9%和79.3%.对比3个预测模型在上证指数股票的预测准确率,T-DBN预测准确率明显高于LSTM和DBN.