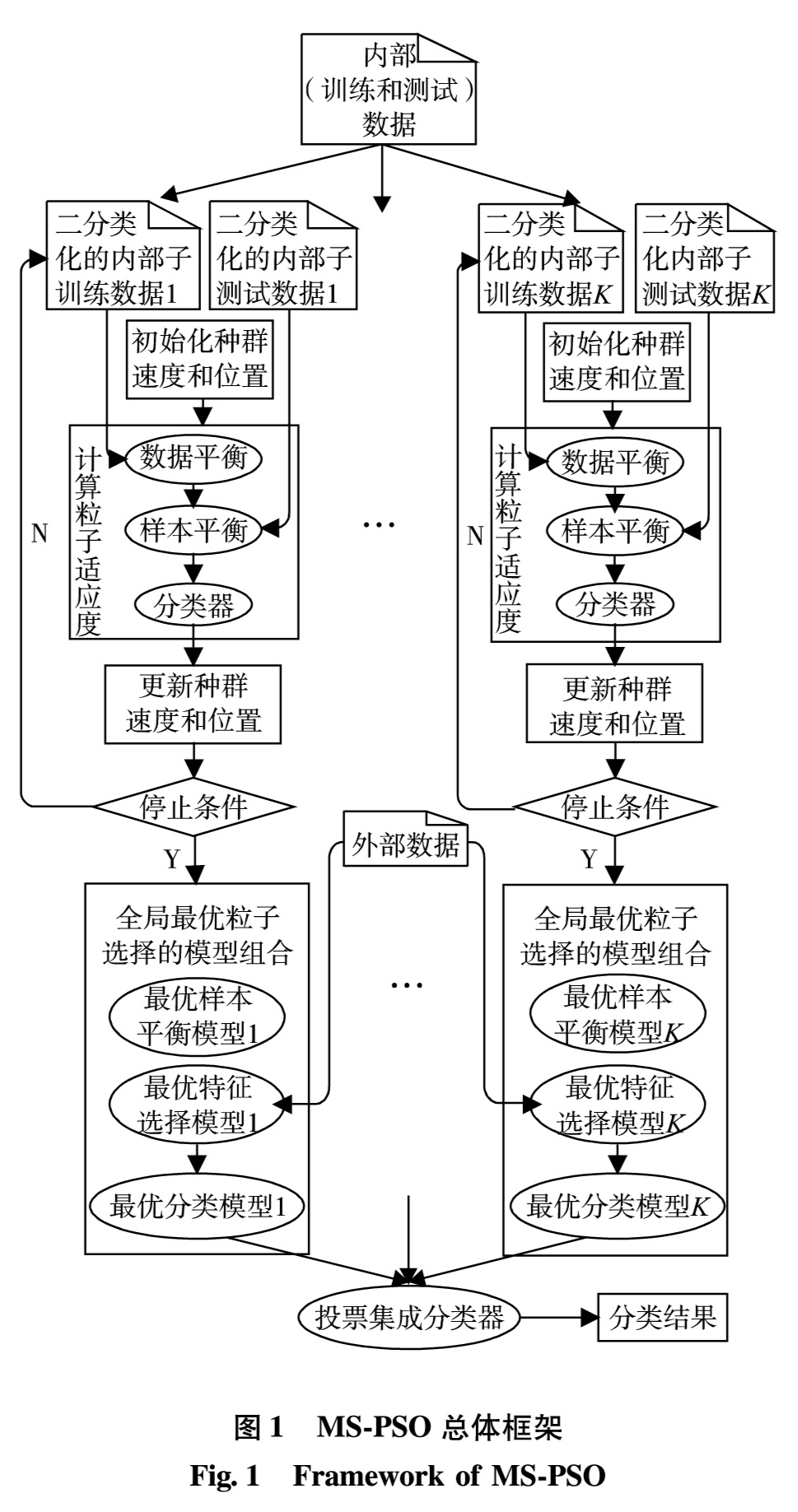
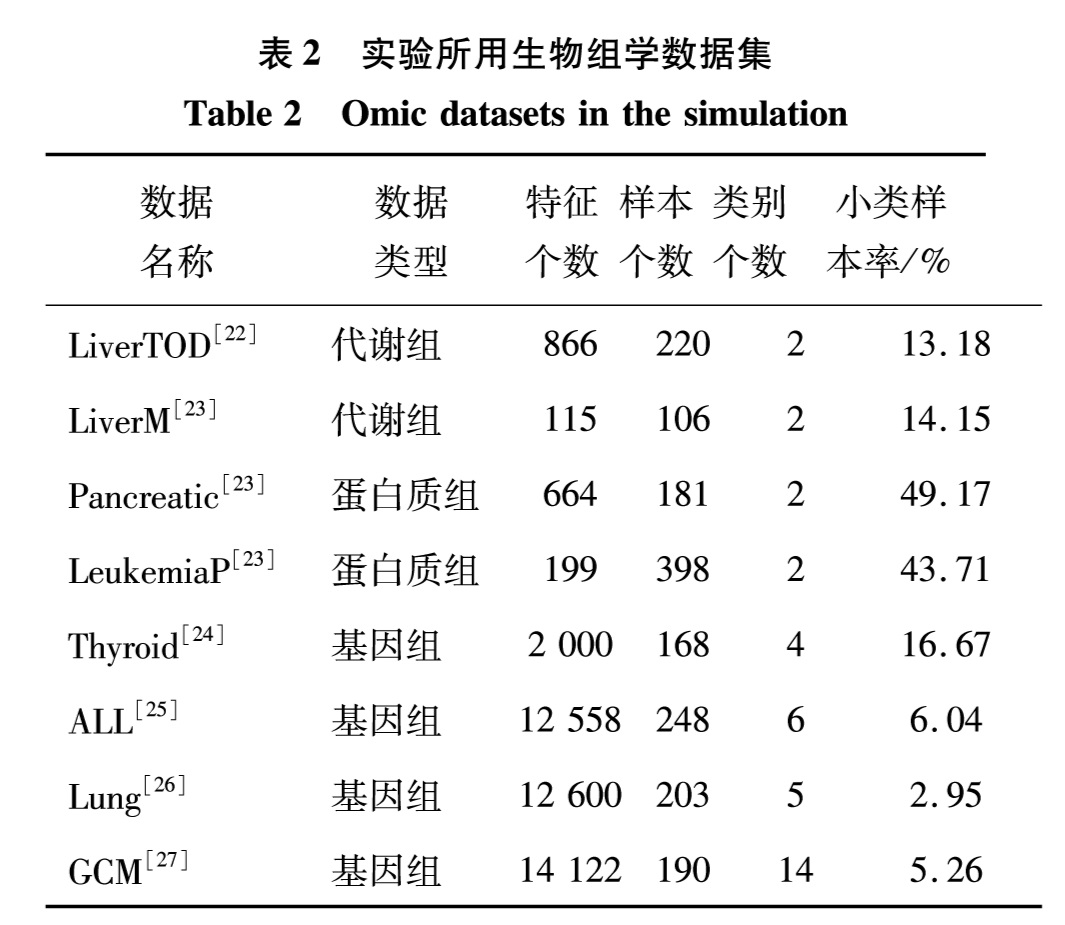
为评估MS-PSO在生物组学数据分类问题上的有效性,在如表2的8组真实生物组学数据上进行分类性能比较测试.这些数据集大都具有较严重的样本不平衡现象.将表1中3种分类模型(KNN、SVM和RF)、3种样本平衡模型(NS、RU和SMOTE)以及3种特征选择模型(FR、FCBF和MRMR)的所有可能的组合称为固定模型选择(fixed model selection,FMS),共3×3×3=27种.实验将MS-PSO和FMS在分类准确率上进行测试并比较优劣.每个FMS超参数由经验设定,如表3.
本研究使用试差法获得PSO最优参数和超参数范围设置,即粒子个数N=20、 I=20、 c1=c2=2、 Ωmax=1、 Ωmin=0. MS-PSO和FMS的性能评估采用外部三折交叉验证,即内部数据用于评估粒子适应度,外部数据用于评估分类性能.首先,评估MS-PSO分类性能.先在整体数据中随机抽取2/3的样本作为计算粒子适应度的内部训练数据,剩下的1/3样本用于MS-PSO分类性能评估.然后,令FMS中的特征选择模型的特征个数与MS-PSO所选择特征的个数保持一致的条件下,完成27种FMS分类性能测试.为减少实验偏差,本研究统计了10次实验分类准确率的平均值,结果如图3.图3中序号坐标28对应MS-PSO,序号坐标1~27对应27种FMS.假设FMS的序号坐标为u, 由式(5)和式(6)可得FMS中所选择的特征选择模型和样本平衡模型.
表2 实验所用生物组学数据集
Table 2 Omic datasets in the simulation
表3 固定模型选择的超参数设置
Table 3 Ultra parameter settings of FMS
FMS={MRMR, u\3=0
FR, u\3=1
FCBF, u\3=2(5)
FMS={NS, u\9={1,2,3}
RU, u\9={4,5,6}
SMOTE, u\9={7,8,0}(6)
其中,符号\表示求余运算.
图3 FMS和MS-PSO实验结果比较
Fig.3 Comparison of simulation results of FMS and MS-PSO
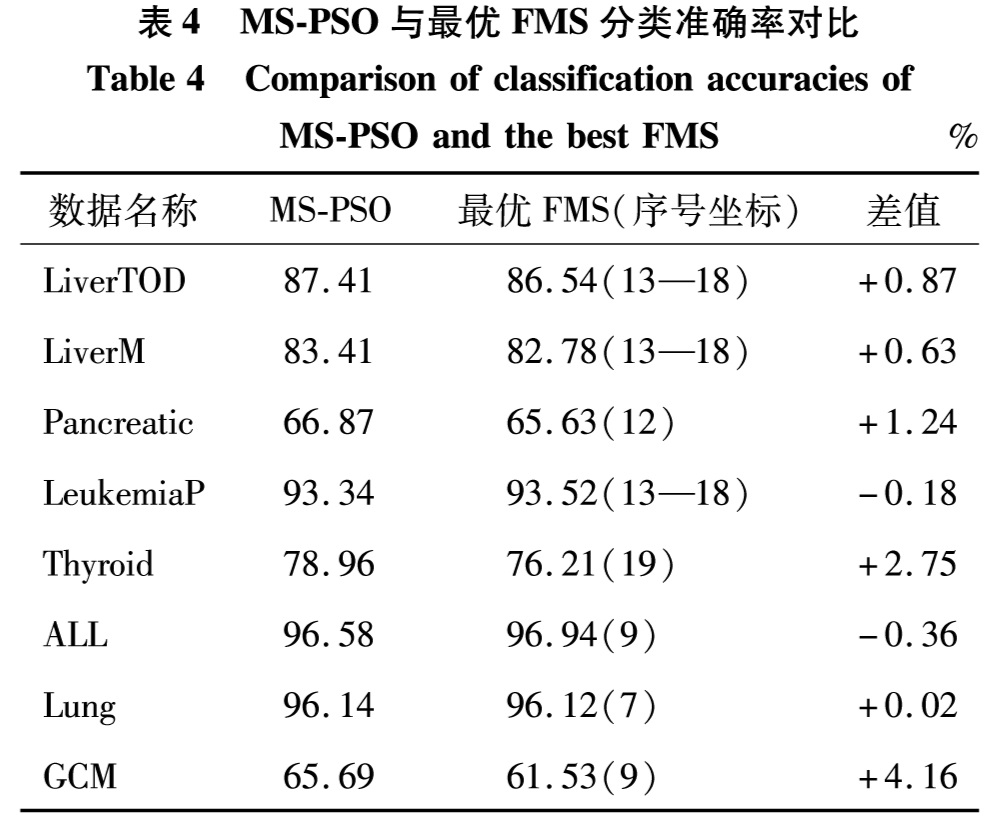
由图3可见,从分类模型角度分析,不同分类模型在不同数据上具有明显的分类性能差异,如KNN在LiverTOD、ALL、Lung和GCM上表现优于SVM和RF,而在其他数据上的表现并不佳.SVM对LiverM和LeukemiaP的分类性能较突出.从样本平衡模型角度分析,数据集LiverTOD、LiverM、Thyroid、ALL、Lung和GCM的样本分布不平衡现象严重,将它们经SMOTE过采样预处理后对分类性能的提升比US和NS更明显,而Pancreatic和LeukemiaP数据集样本分布较为平衡,不对其进行样本平衡预处理反而更有利于分类预测.其原因是类别个数越多,在MS-PSO每个子分类分支中内部子训练数据的样本分布越不平衡,采用SMOTE将样本由不平衡状态转变为平衡状态,会提高小类样本的数量,有益于获得较好的分类预测性能.从特征选择模型角度分析,RF和MRMR通常比FCBF更有助于提高分类性能.由以上分析可知,不存在固定的模型组合能在所有数据上都保持最好的分类性能.表4给出最优的FMS和MS-PSO分类准确率的定量对比.由表4和图3可见,MS-PSO在每个数据上都能达到或接近最突出的分类预测性能.
表4 MS-PSO与最优FMS分类准确率对比
Table 4 Comparison of classification accuracies of MS-PSO and the best FMS %
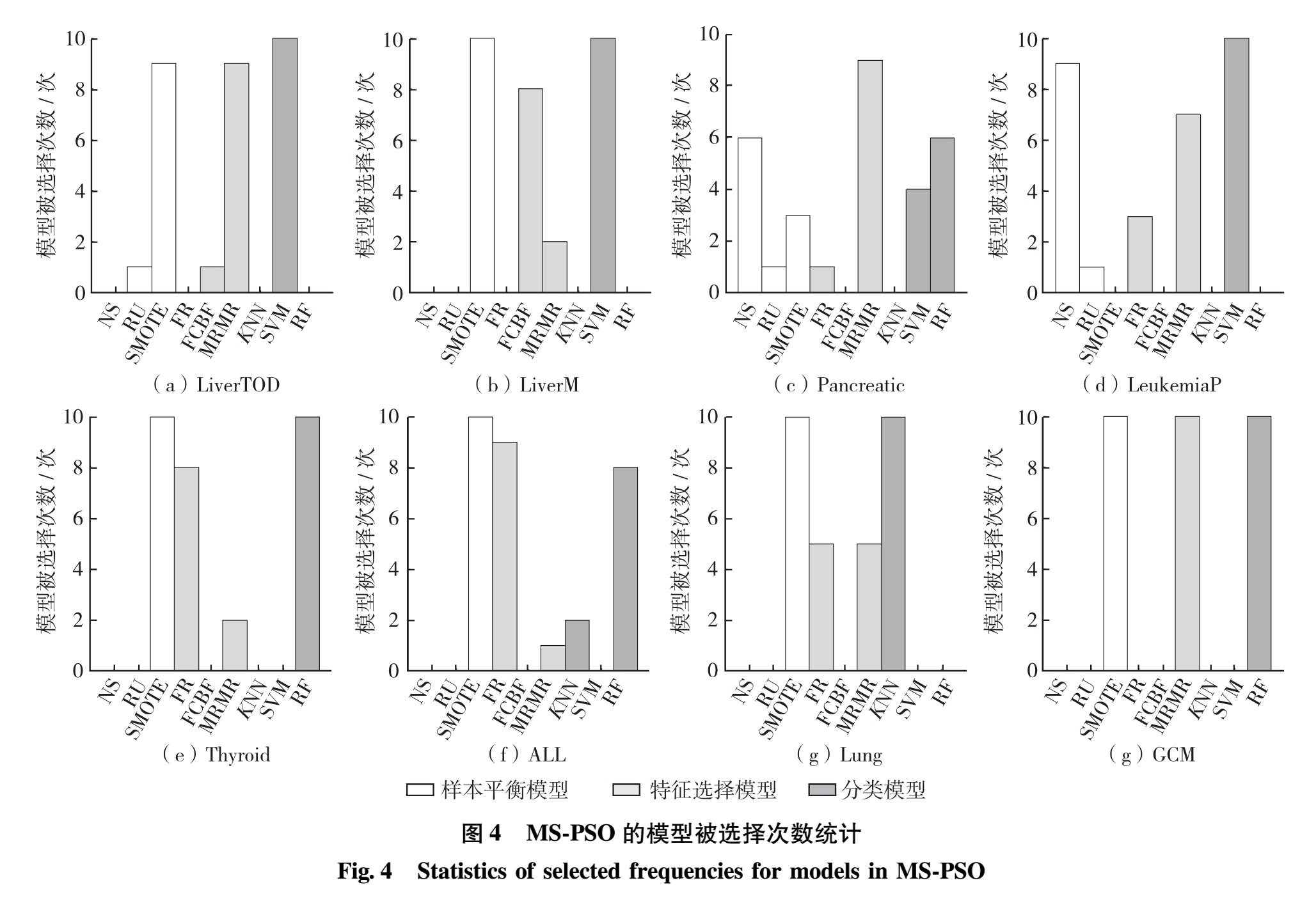
图4给出MS-PSO的最优模型组合中每个模型在10次实验中被选择次数的统计结果.由图4可见,在每组数据中,基本上都存在占支配地位的模型,即该模型被选中的次数明显高于其他模型.这说明MS-PSO能够针对不同生物组学数据样本分布和特征的特点,自适应且稳定地选择到具有最佳分类性能的样本平衡模型、特征选择模型和分类模型的组合,同时获得这组模型的超参数.
图4 MS-PSO的模型被选择次数统计
Fig.4 Statistics of selected frequencies for models in MS-PSO