基金项目:国家自然科学基金资助项目(61261011)
作者简介:甘鹏坤(1991—),男(汉族),河南省信阳市人,南昌大学硕士研究生.E-mail:1158169508@qq.com
中文责编:英 子; 英文责编:雨 辰
作者简介:甘鹏坤(1991—),男(汉族),河南省信阳市人,南昌大学硕士研究生.E-mail:1158169508@qq.com
中文责编:英 子; 英文责编:雨 辰
DOI: 10.3724/SP.J.1249.2015.06563
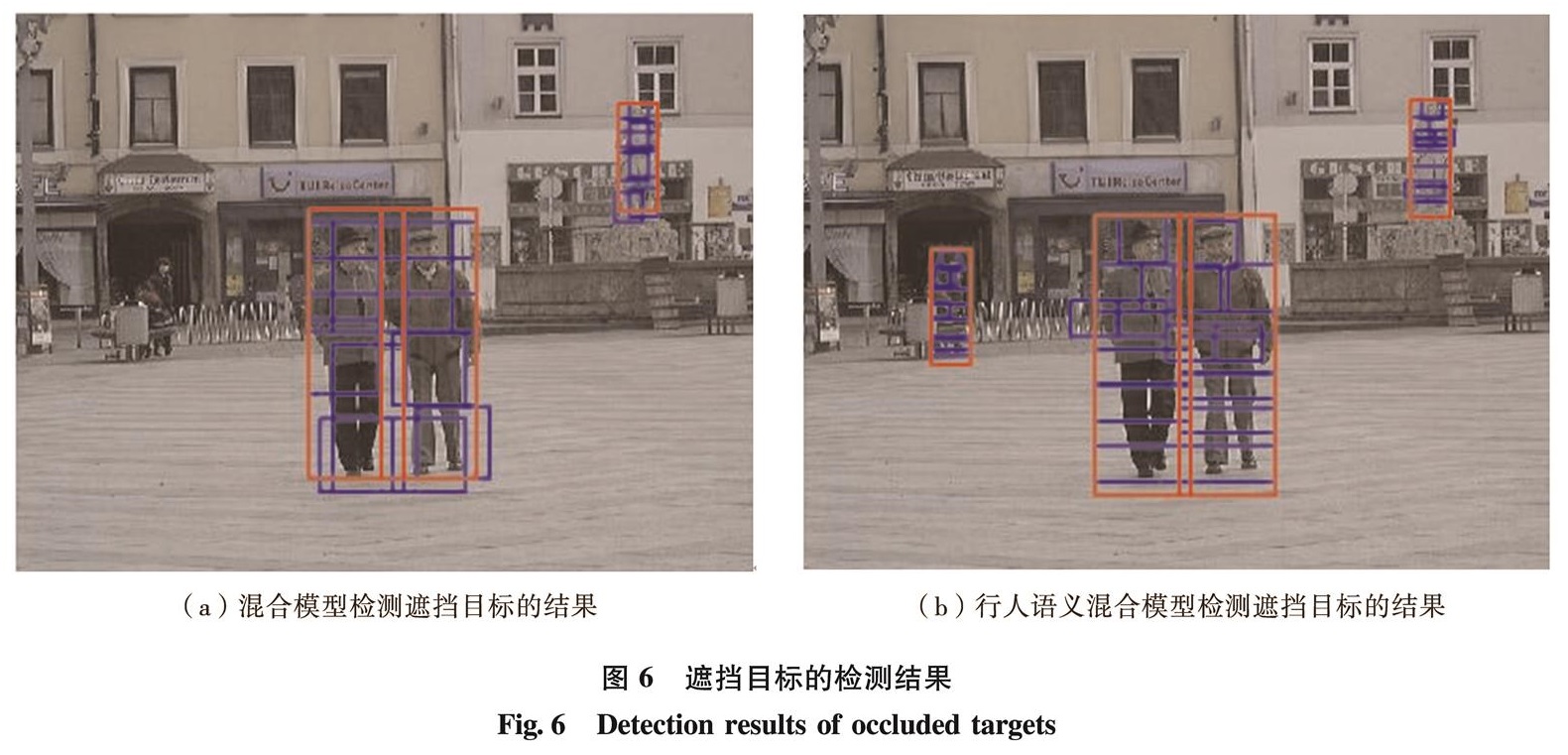
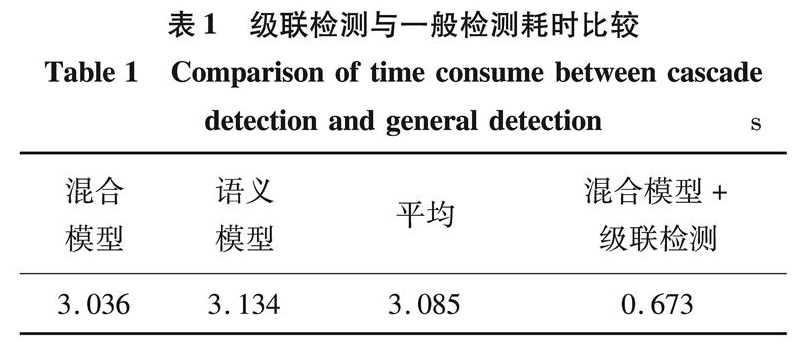
针对方向梯度直方图算法无法处理模糊边界且忽略了物体内平滑的特征区域的问题,提出一种基于稀疏编码的可变形部件模型算法.通过稀疏学习得到稀疏编码直方图特征算子的图像特征,利用弱标签隐藏变量结构化支持向量机学习算法对特征进行训练得到部件模型,再结合级联检测算法对人体目标进行识别检测.实验结果显示,混合模型结合级联方法的检测耗时约是混合模型和语义模型平均检测耗时的1/4,与目前其他已有算法比较,所提方法更加鲁棒和具有识别力.
We propose a new sparse encoding based deformable part modelling method to overcome the defect of histogram of orientation gradients algorithm that can not detect fuzzy boundary and smooth feature region inside an object. By using sparse learning, we obtain the image feature operator based on histograms of sparse codes. We use weak label latent variable structured support vector machine to train the feature to derive part model, which is then combined with cascade algorithm to detect human body targets. Experimental results show that the detection time of hybrid model based on cascade method is about a quater that of the hybrid model alone and semantic model. The proposed method has better robustness and recognition ability.