该函数实现的是LU分解中A及panel内部矩阵的更新操作,其本质是普通双精度矩阵间的乘加运算.本研究利用龙芯处理器提供的向量指令及访存加速部件对其进行优化.
2.1.1 向量化计算
龙芯3B处理器提供了一组256 bit的向量浮点寄存器堆,以及一组针对寄存器堆的向量计算与访存指令.通过向量乘加指令、128 bit访存指令与256 bit寄存器堆的配合,实现矩阵的向量化运算.
向量乘加指令,即在支持向量乘加操作的龙芯3B处理器上,其将分开的乘法和加法指令合并成1条乘加指令. 该指令可在1个时钟周期内完成4次双精度浮点乘加运算,故可大幅提升效率[8].
128 bit向量访存指令,即将普通的64 bit访存指令替换为128 bit向量访存指令,不仅可减少访存指令数,还可提高程序性能.配合向量浮点寄存器的数据置换指令可将4个双精度数据存入256 bit向量浮点寄存器中,满足向量乘加指令要求.
2.1.2 大规模矩阵乘法的分块与预取策略
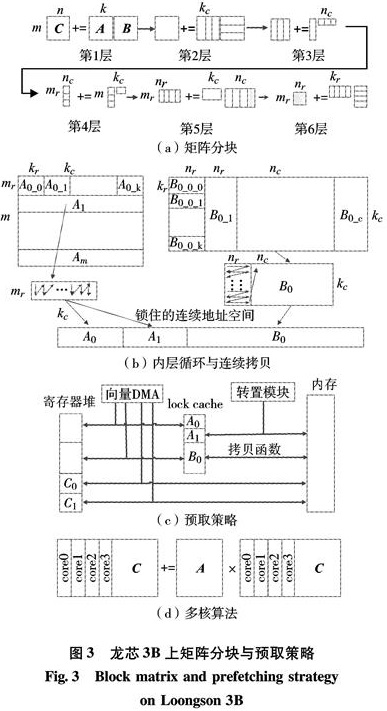
数据分块技术就是通过重新组织数据的访问顺序,减小cache 的失效率来提高程序性能的方法.文献[9]针对矩阵乘法中矩阵分块方法进行了论证,本研究在此基础上针对龙芯3B体系结构及其访存加速部件设计了数据移动代价最小、运算访存比最高的划分方案,如图3(a).
图3 龙芯3B上矩阵分块与预取策略
Fig.3 Block matrix and prefetching strategy on Loongson 3B
通过龙芯3B处理器的cache锁机制,把一些局部性佳的数据和一些被经常调用的子函数(即指令集合)锁在cache中,可降低cache的缺失率,提高整体性能.在矩阵乘法计算中,将图3(a)中第4层mr×kc大小的矩阵 A和kc×nc大小的矩阵 B的小块数据拷贝到连续地址空间,并锁在cache中,如图3(b),将实现矩阵乘加运算的核心函数锁在cache中.这样,在核心循环计算中,取数据和取指令均不会发生cache缺失,提高了执行效率.
图3(c)为龙芯3B上基于访存加速部件的矩阵乘法计算的预取策略.其中,A0和 A1为图3(a)中mr×kc大小的小块矩阵A; B0为kc×nc大小的小块矩阵B(B在计算中会被划分成kc×nr的更小矩阵块与mr×kc大小的矩阵A和mr×nr大小的矩阵C); C0和C1为mr×nr大小的小块矩阵C.
算法具体实现过程为:在计算A0与B0时,通过转置模块将下一块A1预取到锁住的cache中; 在计算C0时利用向量DMA的读通道将下一块矩阵块C1从内存预取到下一组向量寄存器中; 而在计算C1时将通过向量DMA的写通道把矩阵块C0写入内存; 写完后将下一块C2预取到C0存放的寄存器中.在计算mr×nr的小块矩阵C中,参与计算的A和B都是通过向量DMA的读通道从锁住的空间中预取到寄存器中的,每次预取A和B的大小分别为mr×kr和kr×nr.
在龙芯3B中,每4个处理器核为1个节点,它们共享一个矩阵转置模块、L2cache和内存控制器.本研究在龙芯3B的一个节点上采用1进程分4线程计算的模式,线程任务划分如图3(d),将B划为4个部分分别由4个线程计算.由4核共享1个矩阵转置模块, A的预取工作全部由主线程完成.
为达到最佳性能,算法要求使用访存加速部件所实现的读写能被完全掩藏在计算中,即满足式(1)至式(3)的限制.其中,Rcomp为CPU的计算速度; Rmem为从内存中读写的访存带宽; Rcache为向量DMA读写时cache命中的访存带宽.
(2mrnrkr)/(Rcomp)≥(2mrnr)/(Rmem), 即kc≥(Rcomp)/(Rmen)(1)
(2mrnckc)/(Rcomp)≥(mrkc)/(Rmem), 即nc≥(Rcomp)/(2Rmen)(2)
(2mrnrkr)/(Rcomp)≥max((mrkr)/(Rcache),(nrkr)/(Rcache)),
即min(mr,nr)≥(Rcomp)/(2Rmen)(3)
(2mrnrkr)/(mrkr+nrkr)=(2mrnr)/(mr+nr),(4)
2mrnr+smrkr+snrkr≤4M,(5)
其中,M为寄存器堆大小
2mrkc+kcnc≤size of(locked cache)(6)
式(1)保证在完成当前mr×nr大小的矩阵C计算前,向量DMA能将上一轮计算完的C写入内存并读取完下一轮即将参与计算的C值; 式(2)保证在完成mr×kc大小的矩阵A与kc×nc大小的矩阵B计算前,矩阵转置模块能完成下一块mr×kc大小的矩阵A从内存搬到锁住的cache中的预取工作; 式(3)保证核心循环在完成当前mr×kr大小的矩阵A与kr×nr大小的矩阵B计算前,向量DMA能够完成下一轮即将参与计算的mr×kr大小的矩阵 A和kr×nr大小的矩阵 B的预取工作; 式(4)为核心循环中计算与访存之间的比例关系.可见,当mr=nr时计算访存比最大,且比值随mr和nr的增大而增大,即mr和nr的值越大,访存压力越小.
由式(1)和式(2)可知, kc和nc的值越大,向量DMA读写C和转置模块预取A就越能被掩藏在计算中.由式(3)和式(4)可知, mr和nr的值越大,向量DMA的访存压力越小,且A和 B的预取时间就越能被掩盖.但是这些值必须满足式(5)和式(6)所限制的条件:式(5)要求所用向量寄存器不能超过龙芯3B处理器能提供的最大个数; 式(6)要求锁住的 A和 B不能超过龙芯3B处理器可提供的最大锁住空间(s表示 A和 B的寄存器每经过多少次计算后才会重复使用之前的寄存器,kr为每次计算选取几列参与计算.由实验可知,当s=4, kr=2时可获得比较理想的性能).为此,在条件允许的情况下,尽可能增大mr、 nr、 kc和nc的值.
2.1.3 小规模矩阵的乘法优化
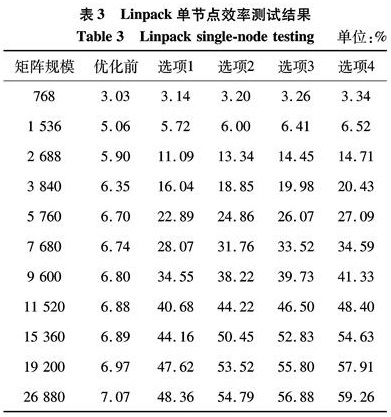
在Linpack算法中为panel内部矩阵更新而调用矩阵乘法运算中,矩阵B的规模k和n都非常小,最大不超过Linpack测试分块M的一半,最小值为2.此时由于k和n非常小,每个局部计算时间都很短,造成向量DMA对数据的读写时间不能被忽略,加之启动向量DMA等需要时间,导致在k和n非常小时,上述算法的性能比使用128 bit向量访存指令直接在内存中进行读写并使用向量乘加指令进行向量化计算的效率低.
此外,龙芯3B处理器的ld指令和$0 寄存器配合使用可实现非阻塞的预取功能,即在不阻塞流水线的情况下,将数据加载到1级数据cache.同时,循环展开和合理的指令调度[10-12]可有效解决因数据相关而产生的流水线中断.因此,在对矩阵乘法向量化计算的同时,结合预取指令、循环展开和合理调度指令可有效提高程序性能.
2.2 dtrsm函数优化
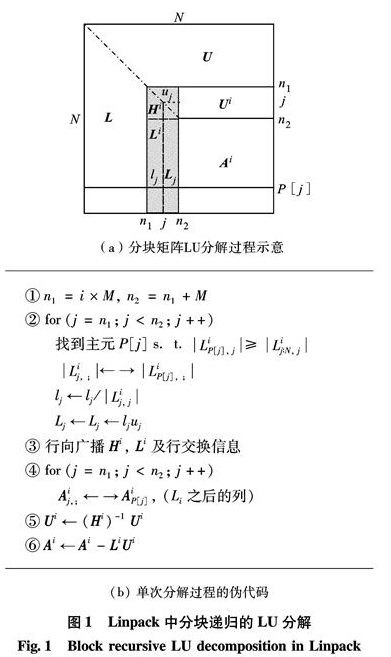
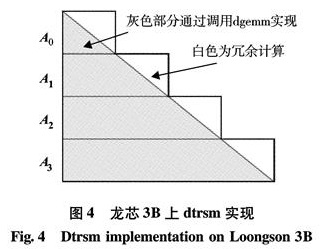
在Linpack测试中,dtrsm函数实现了图1中矩阵U的更新,即一个三角矩阵求逆后与一个矩阵相乘的操作, B=A-1B或 B=BA-1. 未优化时,该函数由于未能充分利用龙芯3B处理器资源而无法达到理想性能,本研究则利用前面针对矩阵乘法优化的方案对该函数进行优化.具体实现如图4,将三角矩阵求逆后存放在锁住的cache中,再分块调用矩阵乘法来实现.
上述算法虽有冗余计算,但相对Linpack调用的原始BLAS库,因该算法充分利用了龙芯3B处理器的cache锁机制、向量指令及访存加速部件,性能较理想.
图4 龙芯3B上dtrsm实现
Fig.4 Dtrsm implementation on Loongson 3B