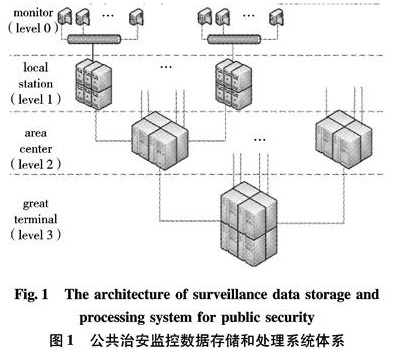
The surveillance data storage and processing system for public security(SDSPS2)can be sketched to be tree-structure distributed system as Fig 1.It consists of 4 layers for now, which are monitor,local station,area center,and great terminal in the bottom-up order.It can be extended to a higher tree structure by inserting more middle layers as the need of the real world grows.Monitor layer is the data source,and other layers are responsible for the data storage and processing.Higher layer nodes are more powerful in capability and performance than the lower ones.We note those nodes of the system in the following order:the great terminal is marked as node T, area centers are noted as node i, i=1,2,…,I, where I is the number of nodes in level 2; local stations under node i are node(i, j), j=1,2,…,Ji, where Ji is the child-nodes number of node i, and the number of monitors is ki, j under node(i, j)correspondingly.
2.2 Level 1:local stations
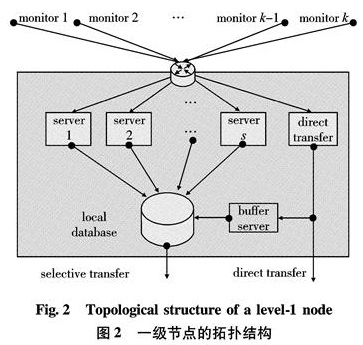
Each local station connects and manages monitors in its territory. Its topological structure is shown in Fig 2.Inside each local station,several servers are deployed to provide service for ongoing video streams.The tasks of those servers are mainly includ:① Storage, they are the interface of local multimedia database for upcoming video streaming.② First-round analysis, they will do the first round analysis, get themeta-data, and build the initial index for each video chuck.
Fig.2 Topological structure of a level-1 node
图2 一级节点的拓扑结构
Due to the shortage of availability or the low utilization rate,those servers may not have enough capacity to respond all the uploading requests to the same time.Therefore,those requests are buffered as a waiting queueing before they can get the service.
Specially,in local station node(i,j), the number of processed servers for ongoing video streams is noted as si, j. In addition,we can assume that the performance factor of each processing server is averagely equal to Pi, j, which is related to its bandwidth and executing ability(e.g. CPU,I/O).
Furthermore,not all the upcoming videos are processed in this layer.Some of them are directly routed to the higher level nodes due to several reasons,so that the higher node needs to aggregate all live video in its territory to do a comprehensive analysis,etc.For similar reasons,video chucks in storage may be selected and pushed to its upper node for further analysis.As a result,we note these two kinds of uploading are “direct transfer” and “selective transfer”,respectively.
2.3 Other levels
Area center is a powerful processing center built upon lots of local stations. Its structure is similar to that of its child nodes. We can mark the number of its processing servers and the performance factor of each server as si and Pi, i=1,2,…,I, correspondingly.
The great terminal is the most high-performance data center in our system.It can collect and analyze data from all its lower level nodes.It has sT processing servers to deal with upcoming videos, each of which has the performance factor PT.
3 System modeling analysis: a queueing
network approach
3.1 Queueing network modeling
A Poisson process is a continuous-time stochastic process,which meets the following conditions:① The time between each pair of consecutive events has an exponential distribution with parameter λ, a.k.a. intensity,which is the expected number of events that occur per unit time.② The number of events in different time intervals is independent from each other.From recent research,the Poisson process is considered a good model for web services among many phenomena[13].
From observations,we can safely assume that the external arrival of uploading requests of the video streaming from monitors,or lower level nodes,follows a Poisson process with an average arrival rate of λ(its value may vary in different cases),and the service time of a job in the queue is exponentially distributed.
Considering the case of a level-1 node(i, j), storing and processing videos is regarded as a job in the queue.The arrival and accomplishment of video streams correspond to the job joining the queue and finishing from the queueing,while other important factors in the queueing model,such as service time and waiting time of a job,can mostly find a good mapping to our real system.It has si, j processing servers for incoming video streaming.We can model it as a queue Qi, j with si, j servers and arrival rate λi, j. We can also get its service rate μi, j=Pi, j/(r0T0)and its service time 1/μi, j, where Pi, j is its performance factor and r0T0 is the size of each video chuck.
As the theory of Poisson process,the sub-flows from stochastically splitting a Poisson flow,or the aggregation of multiple Poisson flows,are still Poisson flows, we can safely infer that the arrival to each queue in each node is Poisson process.Meanwhile,a Jackson network[8] is a network of queues where the arrivals at each queue form a Poisson process,and the job service times are exponentially distributed.An open Jackson network is one with external job arrivals into or departures from the system.As a result,we could model our system as the queueing network,which is also an open Jackson queueing network with several M/M/s/∞ queues,the number of which is equal to the number of datacenter nodes in our system.
We will do a detailed analysis of our system via the following network models.
3.2 Single-source external arrival model
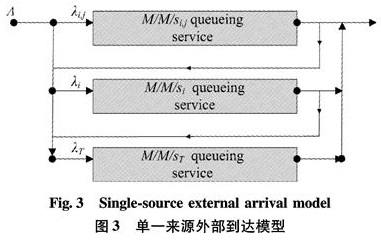
We firstly consider the case that external data source are only from monitors under a single local station,node(i, j). We can build a data model representing this case as Fig 3.
In node(i, j), external arrivals with average arrival rate Λ may join the queue or directly be routed to the higher level node.Let α denote the probability of external arrivals joining the queue in current node.Therefore,for the M/M/si, j/∞ queue Qi, j, we have
{λi, j=αi, jΛ
μi, j=Pi, j/(r0T0)
ρi, j=λi, j/μi, j(1)
where λi, j is the arrival rate,μi, j is the service rate of a single server,Pi, j is its performance factor and r0T0 is the size of each video chuck.To avoid the waiting requests of the queue becoming infinity,we must have enough capability to deal with those requests to keep this system in the stable state.Mapping it into the Jackson network,given the constant factor Pi, j, we must have a sufficient number of processing servers si, j in the queue Qi, j in the equilibrium state,so that the expected sojourn time of each request Ws is no longer than T0, the average time slice of each video streaming.In other words,this condition also means the server utilization ρi, j <si, j.
In the equilibrium of a Jackson network,each of its queue also stays equilibrium, thus we can have the following derivation:
{λi, j=αi, j, 1Λ
λ'i=αi, j, 2Λ+(λi, jβi, j, 1)
λ'T=(1-αi, j, 1-αi, j, 2)Λ+(λi, jβi, j, 2+λ'iβi)
βi, j=βi, j, 1+βi, j, 2<1, βi<1(2)
where λ'i and λ'T is the arrival rate of node i and node T in this single-source case.We note β as the probability of the occurrence of “selective transfer”.Thus βi, j, 1 and βi, j, 2 is the rate of “selective transfer” from node(i, j)to node i and node T respectively,as well as βi for node i to node T.
Fig.3 Single-source external arrival model
图3 单一来源外部到达模型
Based on the queueing theory and Erlang-C formula[5],we can derive the equilibrium distribution of requests in the queue Q as
{p(0)=[∑s-1n=0(ρ0/n!+ρ2/s!(1-ρs)]-1
p(n)={p(0)·(ρn/n!)n=1,2,…,s
p(0)·ρn/(s!sn-s)n>s
ρs=ρ/s=λ/sμ(3)
where p(n)is the probability of n requests on a stable queue.Then we can infer important factors in a queue,such as c(s, ρ), the probability of waiting occurrence in the queue, and Ls, the exected number of requests in the queue,by the following formulae
c(s, ρ)=∑∞n=sp(n)=(ρs)/(s!(1-ρs))·p(0)(4)
Ls=Lq+Lbusy=
∑∞n=s+s(n-s)p(n)+(∑s-1n=0np(n)+∑∞n=ssp(n))=
c(s, ρ)ρs/(1-ρs)+ρ(5)
In the actual computing,it is necessary to avoid computing a big number such as ρs. Thus,the formula of Lq is transformed as the following when computing
Lq=(ρs)/((1-ρs)2)1/(s!∑s-1n=0(ρn-s)/(n!)+1/(1-ρs))≈(ρs)/((1-ρs)2)1/(1/(1-ρs))=(ρs)/(1-ρs)(6)
3.3 Real system model
In the above subsection,we discuss the single-source external arrival model,where the data flow only from node(i, j)to node i or node T. It is not the case in the real world.In our system,there are Ji level-1 nodes under level-2 node i, i=1,2,…,I, where I is the number of nodes in level 2.It means the model is a tree-like network and the external sources are widely distributed on the level-0 layer.We describe the data flow and process between level-1 and level-2 by Fig 4.
Fig.4 Level 1 and level 2 system model
图4 层1和层2的系统模型
From Fig 4,we can see there is no difference for the level-1 node(i, j)from the single-source external arrival model,but the arrival data flow of the level-2 node I becomes multifold.Thus,we have to modify the arrival formula of λi. We can find that the arrival flow of node i is the aggregation of multiple flows from its child-nodes node(i, j), j=1,2,…, Ji. Therefore,we have λi=∑Jij=1λ'i. Similarly,the arrival flow of node T is the summary of ones from all its sub-nodes,λT=∑Ii=1∑Jij=1λ'T. As a result,we can derive the arrival rate of different nodes by the following array of formulae:
{λi, j=αi, j, 1Λi, j
λi=∑Jij=1λ'T=∑Jij=1(αi, j, 2Λi, j+λi, jβi, j, 1)
λT=∑Ii=1∑Jij=1λ'T=
∑Ii=1∑JJij=1[(1-αi, j, 1-αi, j, 2)Λi, j+
λi, jβi, j, 2]∑Ii=1λiβi
αi, j=αi, j, 1+αi, j, 2<1,
βi, j, 1<1, βi, j, 2<1, βi<1(7)
where αi, j, 1 and αi, j, 2 are the probability of the external data flows under node(i, j)joining the queue Qi, j and Qi; βi, j, 1 and βi, j, 2 are the rates of “selective transfer” from node(i, j)to node i and to node T respectively,as well as βi for node i to node T.Meanwhile,(1-αi, j, 1)and(1-αi, j, 2)are known as the “transparent rate” of external flow in queue Qi, j and Qi, respectively.In conclusion,the factors of our system with equilibrium can be conducted and inferred by Eq(1),(3)—(5),and(7).