基金项目:国家自然科学基金资助项目(61171124,60902069)
作者简介:王 娜(1977-),女(汉族),河北省保定市人,深圳大学教授.E-mail:wangna@szu.edu.cn
中文责编:英 子; 英文责编:雨 辰
作者简介:王 娜(1977-),女(汉族),河北省保定市人,深圳大学教授.E-mail:wangna@szu.edu.cn
中文责编:英 子; 英文责编:雨 辰
DOI: 10.3724/SP.J.1249.2014.01035
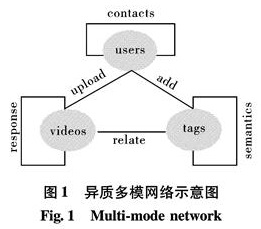
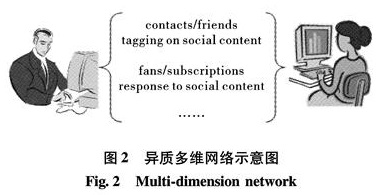
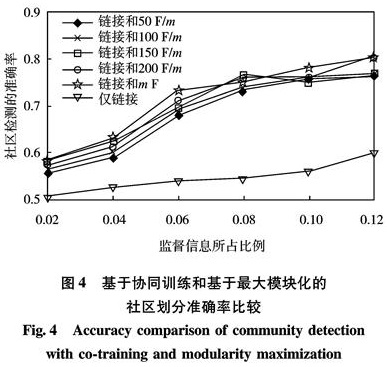
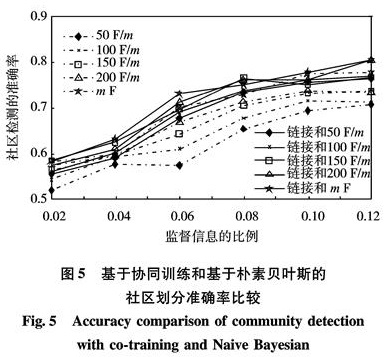
评述基于链接的同质社会网络社区发现方法,介绍基于多维链接关系和多模信息属性的异质网络社区发现方法,指出社会网络个体间不仅存在多种相互联系,其本身还存在描述自身特性的多种特征信息属性; 对社会网络认识的逐渐深入,需融合多方面信息协同处理.根据链接关系矩阵,选取博客平台BlogCatalog,在协同训练框架下融合用户特征信息并进行仿真,模拟异质多模社会网络社区发现.结果表明,对多种链接信息和内容属性信息的融合研究和协同处理可为社会网络社区发现提供准确丰富的信息.
The analysis of social networks, in particular, the discovery of communities within a network, has been a focus of recent research with diverse applications in several fields. In many social networks, there exist different link relations between users while attributes or content information and factors such as demographic details or user-generated content may be associated with those users. In this paper, we outline the state-of-the-art community detection methods based on linked homogeneous social networks. Then, we emphasize community detection in a heterogeneous social network either with multimodal information for each user in the network or with multidimensional relations between users. For the heterogeneous multimode social network, a new community detection method is proposed in the framework of co-training to combine both links and content analysis. Experimental simulations on a real heterogeneous multimode social network dataset were performed and the results have shown that integration of links information and content attributes provided richer and more accurate information for detecting social network community structures.