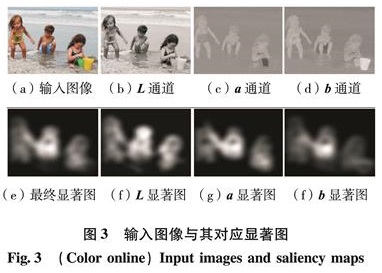
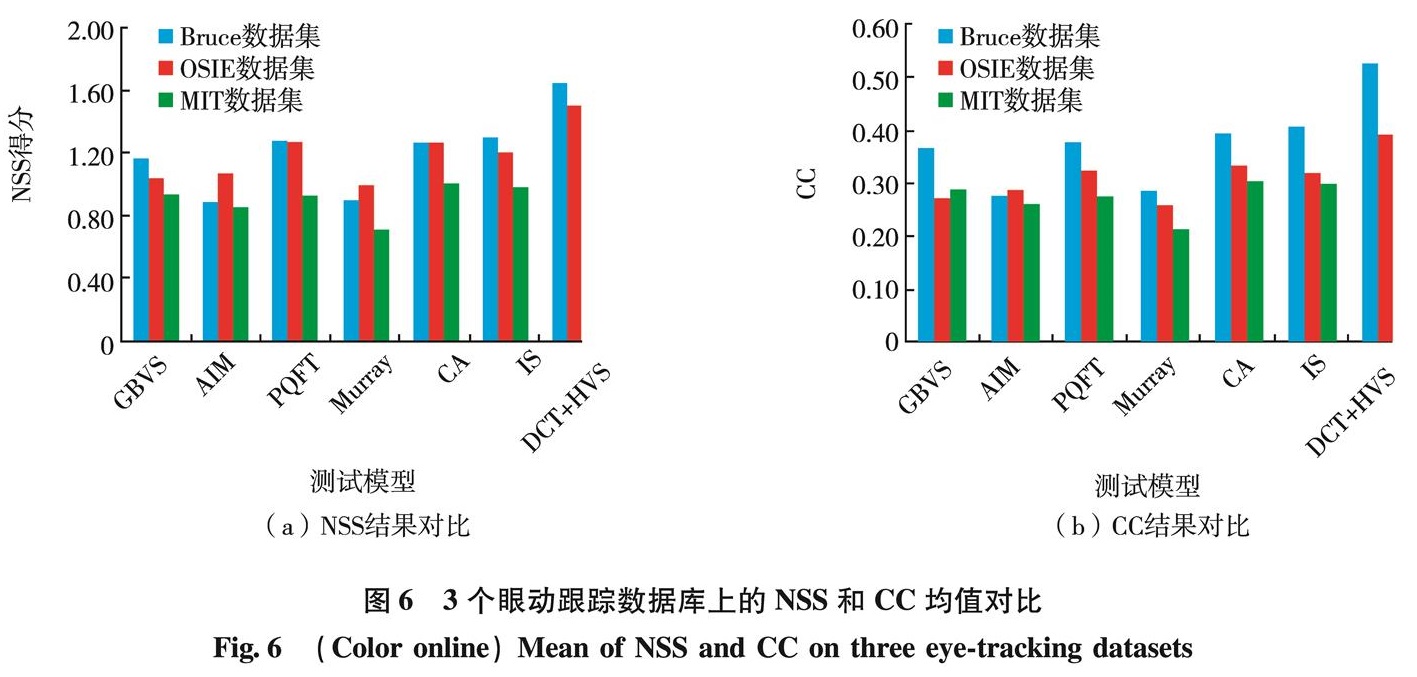
目前,多数显著性检测都是基于特征集成理论的自底向上的模型,该类模型用图像的底层特征,如图像的亮度、颜色、边缘和方向等信息[14]来计算图像的视觉显著性.受IS[11]模型的启发,本研究尝试用图像的亮度和色度的DCT系数作为显著性计算特征.为计算图像的DCT系数,将输入图像从RGB色彩空间转换到CIELab色彩空间.由于图像的显著性表现为每个区域在图像中的对比度,因此本研究将图像分割成互不重叠且大小相同的图像块,对每个图像块所有色彩通道分别做DCT,并将DCT低频系数作为表征该图像块特征的特征向量.每个图像块的显著性定义为该图像块与其他所有图像块之间的空间加权特征差异度之和.本研究提出的显著性检测模型的流程图如图1.
图1 显著性检测流程示意图
Fig.1 (Color online)Saliency detecting flow diagram
首先,输入大小为M×N的RGB彩色图像,并将其转换到CIELab颜色空间.其次,将图像分割成大小为r×c, 且互不重叠的图像块,则总图像块数L=round(M/r)×round(N/c), 其中round()定义为四舍五入操作.每个图像块用pi表示,i=1,2,…,L. 图像块每个通道的特征向量用 Xki表示, k=1,2,3. 每个图像块的显著性定义为
Ski=αi∑j≠iωij·|Xki-Xkj|(1)
其中, |Xki-Xkj|为i和j图像块之间的特征向量之差的绝对值,定义为特征差异度; αi为图像块i的中心偏移权重; ωij为i和j图像块之间的空间距离权重,定义为
ωij=exp(-=pi-pj=/σ2)(2)
这里,=pi-pj=表示图像块i和j之间的欧氏距离; σ2用来调节空间距离对图像块之间特征差异度的影响.
图像中每个图像块的显著性可定义为该图像块在整个图像中的全局对比度,即该图像块与图像中其余所有图像块之间的特征差异度之和.一个图像块与其周围图像块的特征差异度越大,则该图像块的对比度越大,而与距离较远的图像块之间的特征差异度对其全局对比度影响也较小.如式(2),本研究用空间距离的负指数作为每个图像块之间特征差异度的权重.空间距离=pi-pj=越大,则ωij越小,计算得到的特征差异度对该图像块的显著性影响越小.本研究设σ2为0.16.
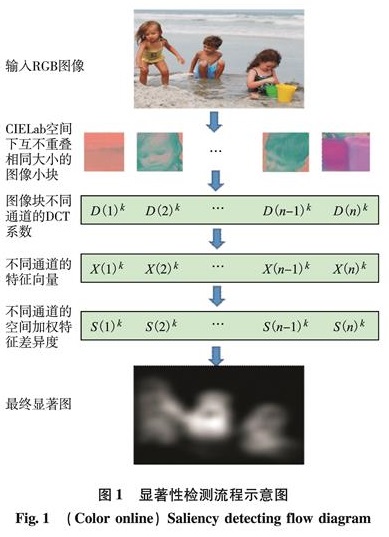
式(1)中的中心偏移权重ai表示每个图像块离图像中心的距离权重,根据HVS原理[13],当人眼视线确定在图像的某个位置时,人眼对该位置的分辨率最高,而离该位置越远的区域人眼分辨率越低.这是因为,在人眼视网膜中,不同区域的视锥细胞密度不同,因此人眼在观看图像时具有不同的视觉灵敏度.人眼视网膜中央凹的视锥细胞密度最大,视觉灵敏度亦最高; 离视网膜中央凹越远的位置,其视锥细胞密度越小.人眼观看距离和视网膜中离心距离之间的关系如图2[13].
图2 观看距离和视网膜离心距离关系[13]
Fig.2 Relationship between viewing distance and retina eccentricity[13]
其中,v为人眼与图像之间的距离,根据一般人眼观看图像时离显示屏的距离,其值设为图像高度的4倍像素; e为图像中(x,y)位置的视线与图像中心点(x0,y0)的视线之间的夹角; d为(x,y)与(x0,y0)的欧氏距离.每个图像块的中心偏移权重定义为
α=exp[-(e+e1)/e1](3)
其中,e1表示半分辨率离心率,根据文献[13]设e1=2.3; e=tan-1(d/v).
HVS表现为离视网膜中央凹处越远的区域,视锥细胞密度越低,视觉灵敏度就越低.因此当人眼观看一张图像时,离眼睛注视点越远的区域,人眼对该区域的分辨率也就越低.人在正面观看图像时,视线一般会首先集中到图像的中心位置,然后再向周围扩散,因此,算法对基于视觉灵敏度计算出的中心偏移权重归一化后给每个图像块的显著度进行了加权.
![图2 观看距离和视网膜离心距离关系[13]<br/>Fig.2 Relationship between viewing distance and retina eccentricity[13]](2014年05期/pic20.jpg)